In the previous chapter we saw how to create a project with Hasura and Docker in a matter
of minutes with docker-compose up -d we have launched a GraphQL API ready to use from the configuration of the docker-compose
file indicated in the Hasura official documentation.
GraphQL mainly specifies three kinds of operations:
- Query: Request data.
- Mutation: Create, update or delete.
- Subscription: Real-time management.
GraphQL
Query
Queries are the most common form of interaction with a GraphQL API. Like a classic database query, it allows us to obtain information from the server, in this case through the API previously exposed under security conditions. Hasura allows us to manage roles and permissions to limit the information that is exposed but we will see that in another chapter.
We can for example obtain the id (internal ID), title (Title) and created_at (Date of creation) of all the tasks with the query:
REQUEST
query AllTasksQuery{
task {
id
title
created_at
}
}
RESPONSE
{
"data": {
"task": [
{
"id": 8,
"title": "Cleaning the house",
"created_at": "2022-11-30T11:20:46.148+00:00"
},
{
"id": 12,
"title": "Create a task list",
"created_at": "2022-12-13T00:31:17.686201+00:00"
},
{
"id": 10,
"title": "Writing a report",
"created_at": "2022-07-17T00:10:33.29+00:00"
},
...
]
}
}
We can also set a limit of two tasks with the limit option:
REQUEST
query AllTasksQuery{
task(limit: 2) {
id
title
created_at
}
}
RESPONSE
{
"data": {
"task": [
{
"id": 8,
"title": "Cleaning the house",
"created_at": "2022-11-30T11:20:46.148+00:00"
},
{
"id": 12,
"title": "Create a task list",
"created_at": "2022-12-13T00:31:17.686201+00:00"
}
]
}
}
It returns the first two tasks of the database, a query that we can combine with a sort by date operation.
REQUEST
query LimitedTasksQuery{
task(limit: 2, order_by: {created_at: desc}) {
id
title
created_at
}
}
RESPONSE
{
"data": {
"task": [
{
"id": 19,
"title": "Buy shortbread",
"created_at": "2022-12-13T01:29:53.106341+00:00"
},
{
"id": 17,
"title": "Visiting the family",
"created_at": "2022-12-13T01:28:04.622421+00:00"
}
]
}
}
The where parameter allows us to filter the results of the query, in this case for example we will receive only
those tasks created after December 1, 2022:
REQUEST
query FilteredTasksQuery{
task(where: {created_at: {_gt: "2022-12-01"}}) {
id
title
created_at
}
}
RESPONSE
{
"data": {
"task": [
{
"id": 12,
"title": "Create a task list",
"created_at": "2022-12-13T00:31:17.686201+00:00"
},
{
"id": 13,
"title": "Walking the dog",
"created_at": "2022-12-13T01:13:49.136216+00:00"
},
{
"id": 14,
"title": "Doing sports",
"created_at": "2022-12-13T01:16:35.274353+00:00"
},
...
]
}
}
Each of the functionalities offered by GraphQL can be combined with each other to adjust the response of the server to the client’s needs. In this case we add a sorting by date of creation in ascending order:
REQUEST
query FilteredTasksQuery{
task(order_by: {created_at: asc}, where: {created_at: {_gt: "2022-12-01"}}) {
id
title
created_at
}
}
RESPONSE
"data": {
"task": [
{
"id": 7,
"title": "Planning a party",
"created_at": "2022-12-03T05:45:22.096+00:00"
},
{
"id": 5,
"title": "Create a budget",
"created_at": "2022-12-06T10:28:59.551+00:00"
},
{
"id": 1,
"title": "Make a shopping list",
"created_at": "2022-12-09T01:37:55.790089+00:00"
},
...
]
}
}
We can also filter variables by text, for example by collecting all the tasks whose creation user matches a specific name:
REQUEST
query FilteredTasksQuery{
task(where: {user: {name: {_eq: "Alfred"}}}) {
user {
name
}
id
title
created_at
}
}
RESPONSE
{
"data": {
"task": [
{
"user": {
"name": "Alfred"
},
"id": 12,
"title": "Create a task list",
"created_at": "2022-12-13T00:31:17.686201+00:00"
},
{
"user": {
"name": "Alfred"
},
"id": 7,
"title": "Planning a party",
"created_at": "2022-12-03T05:45:22.096+00:00"
},
{
"user": {
"name": "Alfred"
},
"id": 5,
"title": "Create a budget",
"created_at": "2022-12-06T10:28:59.551+00:00"
},
...
]
}
}
So far we have been entering the data directly into the query but we also have the possibility of using variables in GraphiQL by clicking on the dollar sign next to the parameter.
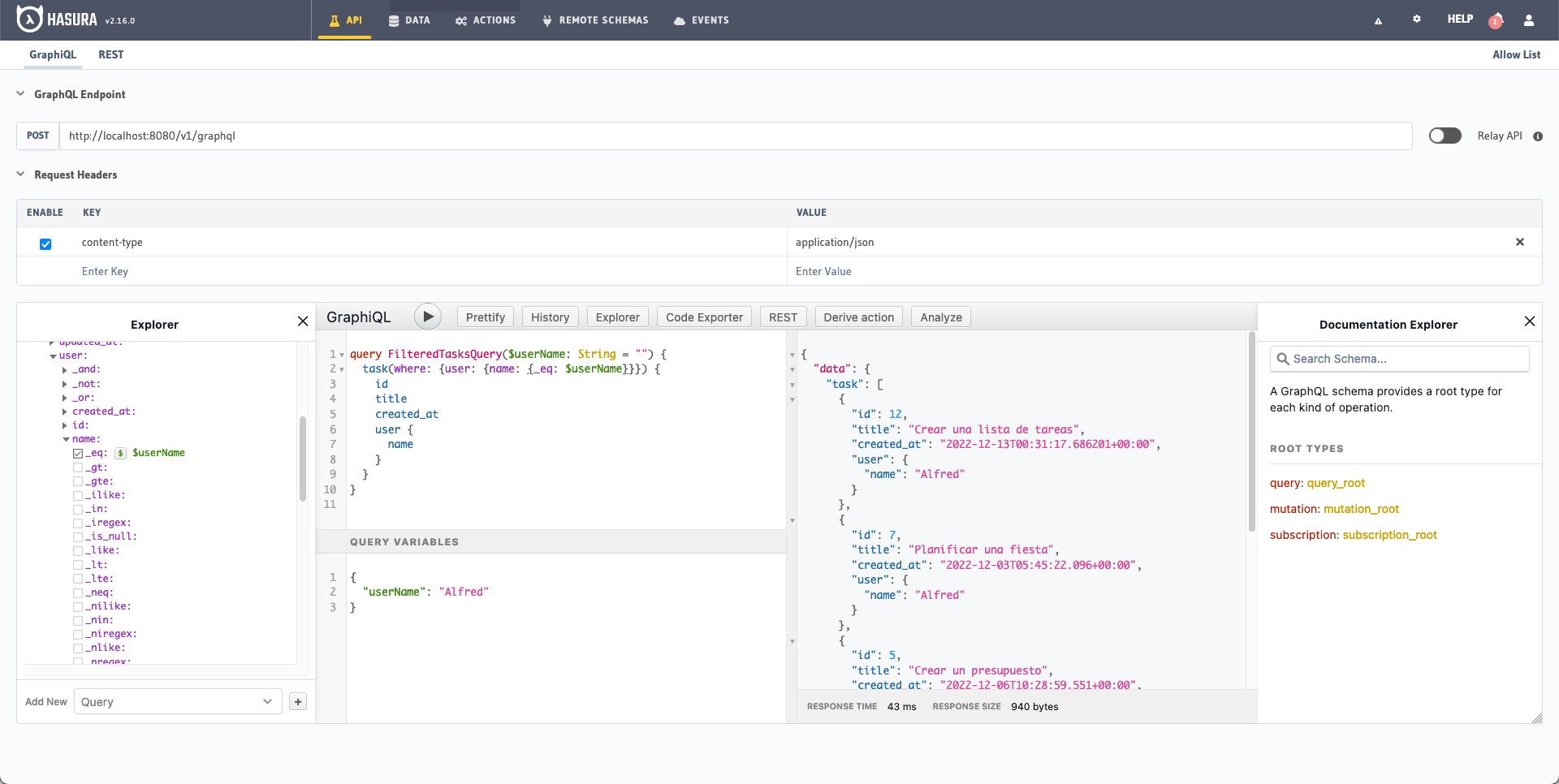
REQUEST
query FilteredTasksQuery($userName: String!){
task(where: {user: {name: {_eq: $userName}}}) {
user {
name
}
id
title
created_at
}
}
In the lower box Query Variables we can enter in JSON format the variables that we are going to use in the query:
VARIABLES
{
"userName": "Alfred"
}
RESPONSE
{
"data": {
"task": [
{
"user": {
"name": "Alfred"
},
"id": 12,
"title": "Create a task list",
"created_at": "2022-12-13T00:31:17.686201+00:00"
},
{
"user": {
"name": "Alfred"
},
"id": 7,
"title": "Planning a party",
"created_at": "2022-12-03T05:45:22.096+00:00"
},
{
"user": {
"name": "Alfred"
},
"id": 5,
"title": "Create a budget",
"created_at": "2022-12-06T10:28:59.551+00:00"
},
...
]
}
}
We can also get all those tasks that contain the word home in their title:
REQUEST
query FilteredTasksQuery{
task(where: {title: {_like: "%home%"}}) {
id
title
created_at
}
}
RESPONSE
{
"data": {
"task": [
{
"id": 8,
"title": "Cleaning the house",
"created_at": "2022-11-30T11:20:46.148+00:00"
}
]
}
}
The offset allows us to skip a number of results, for example to get the tasks starting from we skip the first two:
REQUEST
query FilteredTasksQuery{
task(offset: 2) {
id
title
created_at
}
}
RESPONSE
{
"data": {
"task": [
{
"id": 10,
"title": "Writing a report",
"created_at": "2022-07-17T00:10:33.29+00:00"
},
{
"id": 13,
"title": "Walking the dog",
"created_at": "2022-12-13T01:13:49.136216+00:00"
},
{
"id": 14,
"title": "Doing sports",
"created_at": "2022-12-13T01:16:35.274353+00:00"
},
...
]
}
}
Mutation
In GraphQL a mutation is an operation that allows to modify the server data. It is similar to a query but instead of fetching data (beyond the newly created data), it performs an action that modifies some aspect of the server state.
To add a new user or a task we can use the following mutation. In this first call we add a new user by entering the parameters directly in the code:
MUTATION
mutation InsertUserMutation {
insert_user(objects: {
uid: "25d4c7b0-1b5a-4b9e-8c5a-2c7f3a7478e9",
username: "monique",
name: "Monique"}) {
affected_rows
returning {
id
name
}
}
}
RESPONSE
{
"data": {
"insert_user": {
"affected_rows": 1,
"returning": [
{
"id": 10,
"name": "Monique"
}
]
}
}
}
This one allows us to insert a new task using variables. In our example, the task_insert_input class is generated by
Hasura automatically and defines the fields that we can use to insert a new task.
MUTATION
mutation InsertTaskMutation($objects: [task_insert_input!] = {}) {
insert_task(objects: $objects) {
affected_rows
returning {
id
title
created_at
}
}
}
Passing the parameters back to it through variables in JSON format:
VARIABLES
{
"objects": {
"title": "Write an article",
"uid": "486a4252-6576-45d3-bc9a-1d6f0388b581",
"user_id": 6
}
}
RESPONSE
{
"data": {
"insert_task": {
"affected_rows": 1,
"returning": [
{
"id": 21,
"title": "Write an article",
"created_at": "2022-12-20T22:30:23.434237+00:00"
}
]
}
}
}
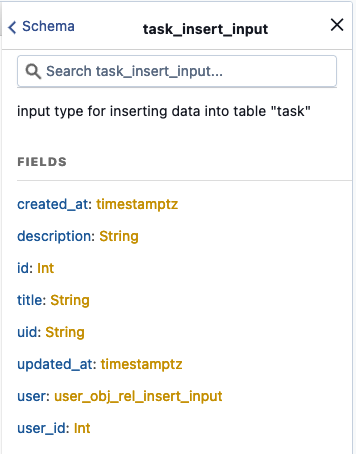
In the right pane of Hasura called Documentation Explorer we find the documentation generated to view the fields required
by our queries, as the task_insert_input class in the example:
Subscription
Subscriptions (subscription) allows us to communicate in real time and bidirectionally with the server, updating the information on the clients immediately. It uses the WebSockets technology to maintain an open channel to communicate without needing to restart the connection.
Its excessive use can lead to a high consumption of resources and depending on the project, may not be necessary or may add complexity to the implementation. We could create a subscription to have the list of users updated in real time:
subscription AllUsersSubscription {
user {
id
name
}
}
We can also use filtering and sorting as in this example to get the tasks of all users named Bob:
subscription BobTasksSubscription {
task(where: {user: {name: {_eq: "Bob"}}}) {
id
title
created_at
}
}
To see the results of live subscriptions I recommend the video below.
Fragments are not operations in themselves but it is not superfluous to mention them as they usually accompany these operations because they allow us to reuse parts of the queries and create a kind of templates to avoid repeating code and simplify the organization.
These are the basic operations that we can perform with GraphQL, to see the Fragment, custom data types
and other details everything is perfectly defined in the official specification.
Findings
In my opinion it is a language with a fairly simple syntax but with a spectacular flexibility when designing and structuring queries that allows us to create applications in an efficient way. Everything depends on the needs of each project.
Related
- Part 1: https://betazeta.dev/blog/docker-hasura-graphql/
- Part 3: https://betazeta.dev/blog/docker-hasura-graphql-3/
- GraphQL: https://graphql.org/
- GraphQL specification: https://spec.graphql.org/draft/