As databases grow larger and more complex, managing and accessing data efficiently becomes increasingly challenging. This is where database views come into play. A view acts as a “window” into the data stored in your database. Think of it as a predefined query that displays a subset of data from one or more tables. Unlike traditional tables, views don’t physically store data; they simply serve as an abstraction layer.
What Are Database Views?
Picture an e-commerce database with multiple tables: customers, orders, products, payments, etc. If a business analyst needs to see a summary of customer purchases without dealing with the complex database structure, a view can streamline this task by presenting the information in a clear, accessible format.
Use Cases
Database views are powerful tools that excel in various scenarios:
- Simplifying Complex Queries: Instead of writing lengthy SQL queries repeatedly, you can create a view that encapsulates the logic and makes it reusable.
- Security and Access Control: Views can restrict access to sensitive data, showing only necessary information without exposing confidential internal data.
- Application Compatibility: When an application depends on a specific data structure, views can act as a “bridge” between old and new structures without modifying the application code.
- Performance Optimization: While regular views don’t store data, some database engines offer materialized views that cache query results for improved performance in intensive use cases.
Despite their advantages, views aren’t a silver bullet. They can impact performance if misused, especially when running on heavy queries or large datasets. Additionally, some views don’t allow direct data modifications, which might be limiting in certain scenarios.
To put these concepts into practice, let’s work with a realistic dataset. We’ll create a database with a typical e-commerce structure and use views to extract useful information efficiently.
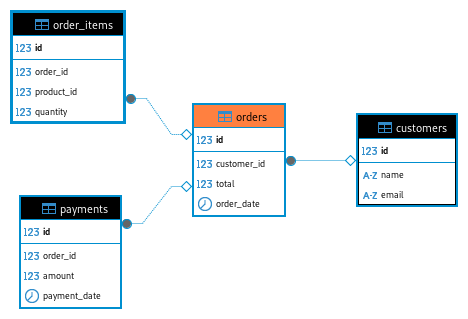
Our goal is to demonstrate how views can simplify queries, optimize data access, and facilitate managing key information like order status, best-selling products, and payment tracking. Here’s our database structure:
- customers – Customer information
- orders – Customer orders
- order_items – Products included in each order
- products – Available store products
- payments – Order payments
Setting Up PostgreSQL Database
Let’s start by spinning up a PostgreSQL database using Docker:
docker run -d \
--name ecommerce_db \
-e POSTGRES_USER=admin \
-e POSTGRES_PASSWORD=admin \
-e POSTGRES_DB=ecommerce \
-p 5432:5432 \
-v pgdata:/var/lib/postgresql/data \
postgres:latest
You can connect to it using your preferred method, whether it’s a GUI tool like DBeaver or the command line. I personally prefer graphical interfaces when they offer the essential features, so we’ll use DBeaver. Simply add a new PostgreSQL connection with these details:
- Host: localhost
- Port: 5432
- Database: ecommerce
- User: admin
- Password: admin
// …existing code for SQL table creation…
Populating the Database
We can use any AI tool to help us generate sample data INSERT statements. I used ChatGPT for this purpose, and here’s what it suggested:
// …existing code for INSERT statements…
Creating PostgreSQL Views
Now that our database is populated with sample data, let’s create some useful views. One common e-commerce requirement is getting order information along with customer details without writing multiple JOINs every time.
Customer Orders View
// …existing code for customer_orders view…
This view, named customer_orders, combines relevant order information with associated customer data. Instead of writing a complex query each time we need this information, we can simply query the view:
SELECT * FROM customer_orders;
We might also want to analyze our store’s most popular products by creating a view showing total units sold per product.
Top Selling Products View
// …existing code for top_selling_products view…
To track our store’s financial performance, let’s create a view for monthly revenue analysis.
Monthly Revenue View
// …existing code for monthly_revenue view…
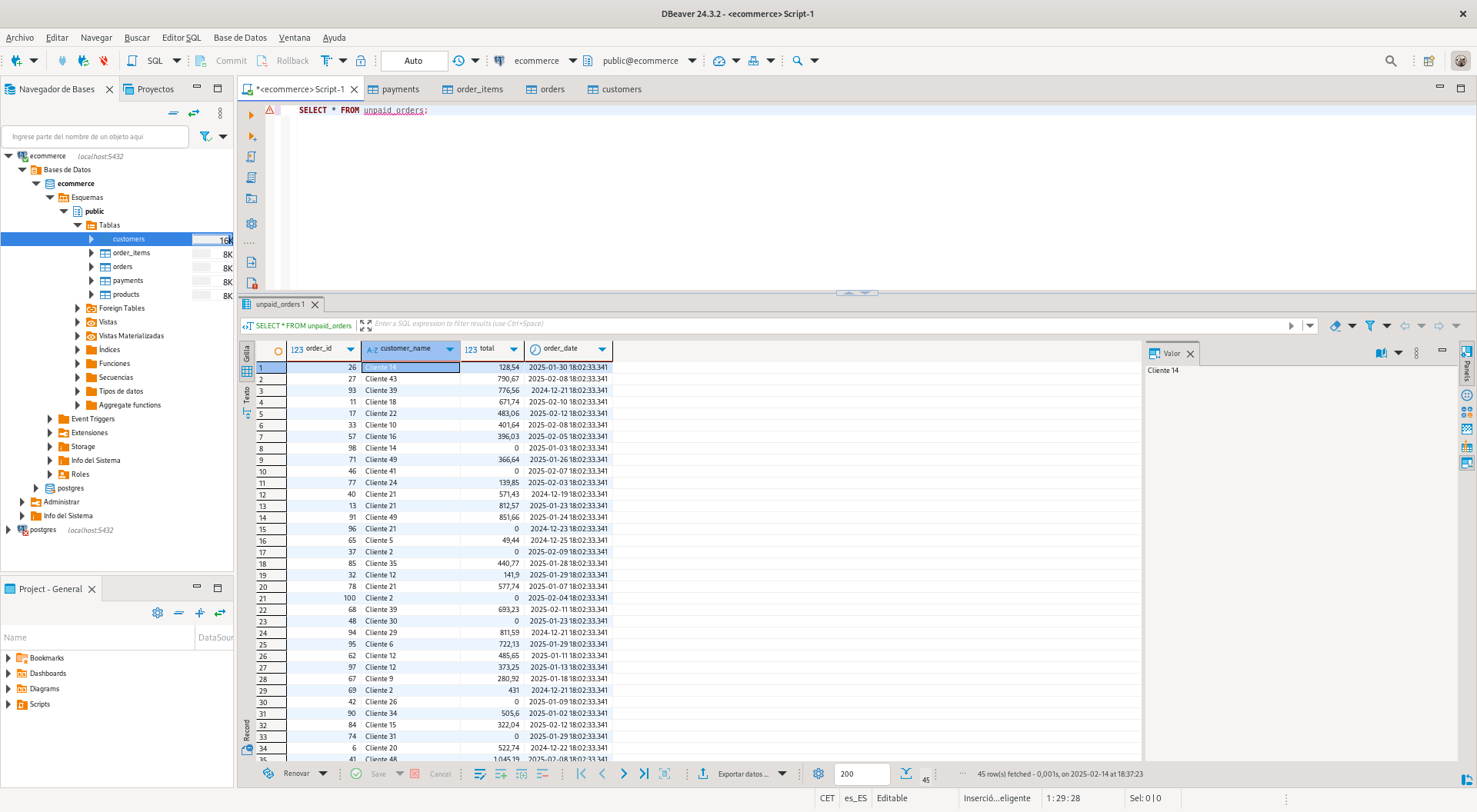
Some orders might be created without associated payments. This view helps identify unpaid orders.
Unpaid Orders View
// …existing code for unpaid_orders view…
Finally, let’s create a comprehensive view that shows detailed information about unpaid orders including customer data:
Detailed Unpaid Orders View
// …existing code for detailed_unpaid_orders view…
A simple query to the detailed_unpaid_orders view will give us all the necessary information about unpaid orders:
SELECT * FROM detailed_unpaid_orders;
This approach not only simplifies database queries but also serves as a template for generating reports in our application. Sometimes, it’s more efficient to let the database handle data processing rather than complicating application logic.
As mentioned earlier, not everything should be handled through views, and not all processing should happen in the database. Depending on your application’s needs and circumstances, you’ll need to choose the most appropriate approach considering all factors involved.
Conclusion
Whether you’re new to database views or just needed a refresher, I hope this article has helped clarify their purpose and usage. I encourage you to explore this topic further and share your experiences. Above all, Happy Coding!