An overview of the most common commands in …
In the previous chapter, we reviewed the origins and fundamentals of databases. We took a brief …
read moreIn this series, we’ve explored various database engines, such as SQLite, and the fundamental concepts of the relational model. Now, we’ll dive into PostgreSQL, a relational database management system (RDBMS) widely recognized for its robustness, scalability, and extensibility. Designed for complex applications, PostgreSQL combines a client-server architecture with advanced support for multiple users and specialized features. Its versatility makes it an ideal choice for both enterprise projects and personal developments.
Like other relational engines such as SQLite, PostgreSQL uses SQL (Structured Query Language) to interact with data.
However, it stands out by offering advanced features such as support for JSON/JSONB, modular extensions, and efficient
concurrency management. These make PostgreSQL particularly suitable for applications requiring flexibility, high
availability, and efficient handling of large volumes of data.
In this article, we will set up PostgreSQL in a virtualized environment using Docker and design a database to model a transportation network. This practical exercise will include One-to-One, One-to-Many, and Many-to-Many relationships, allowing you to practice fundamental concepts of the relational model while exploring PostgreSQL’s capabilities. Additionally, we will lay the groundwork for future explorations of its advanced features.
To run PostgreSQL in a local environment and connect to it using a database management client such as DBeaver or PgAdmin, you can use Docker. This will allow you to quickly set up a clean and controlled environment without needing to install PostgreSQL directly on your system.
Run the following command to create and launch a PostgreSQL container:
docker run --name postgres-transport -e POSTGRES_PASSWORD=secret -d -p 5432:5432 postgres
If you’re not familiar with Docker, you can check out our series on Docker and return to this point once you feel comfortable. That said, this command will perform the following steps:
postgres-transport.postgres) as secret.Once the container is running, you can use an SQL client to connect to the database. The required credentials are:
Host: localhost
Port: 5432
User: postgres
Password: secret
Database: postgres (default database)
In this example, we’ll use DBeaver as our SQL client, but feel free to use any other tool you prefer. Follow these steps to connect to the database:
Once connected, you can use DBeaver’s graphical interface to manage your database, add, modify, and delete tables, as well as execute SQL queries and much more.
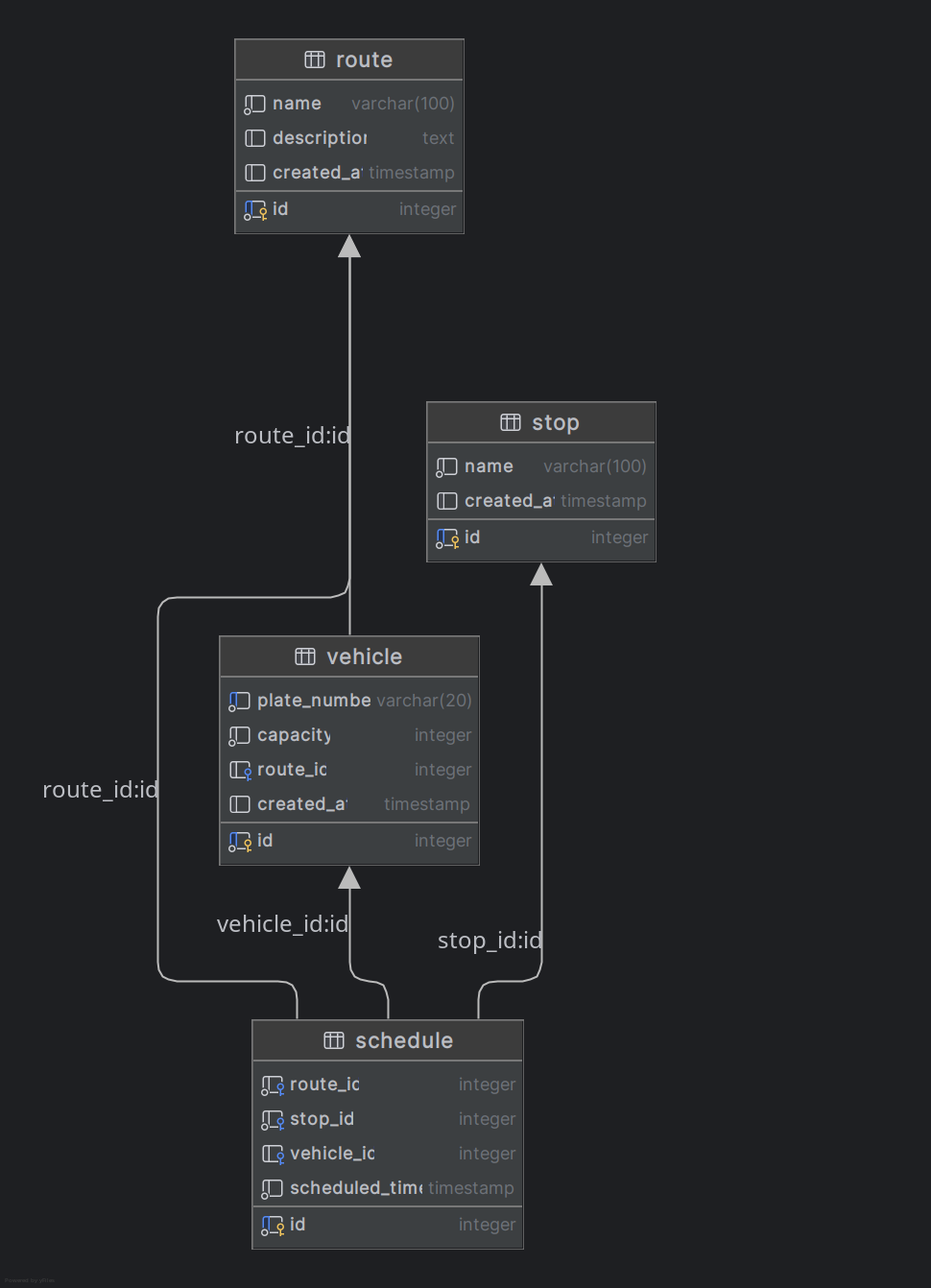
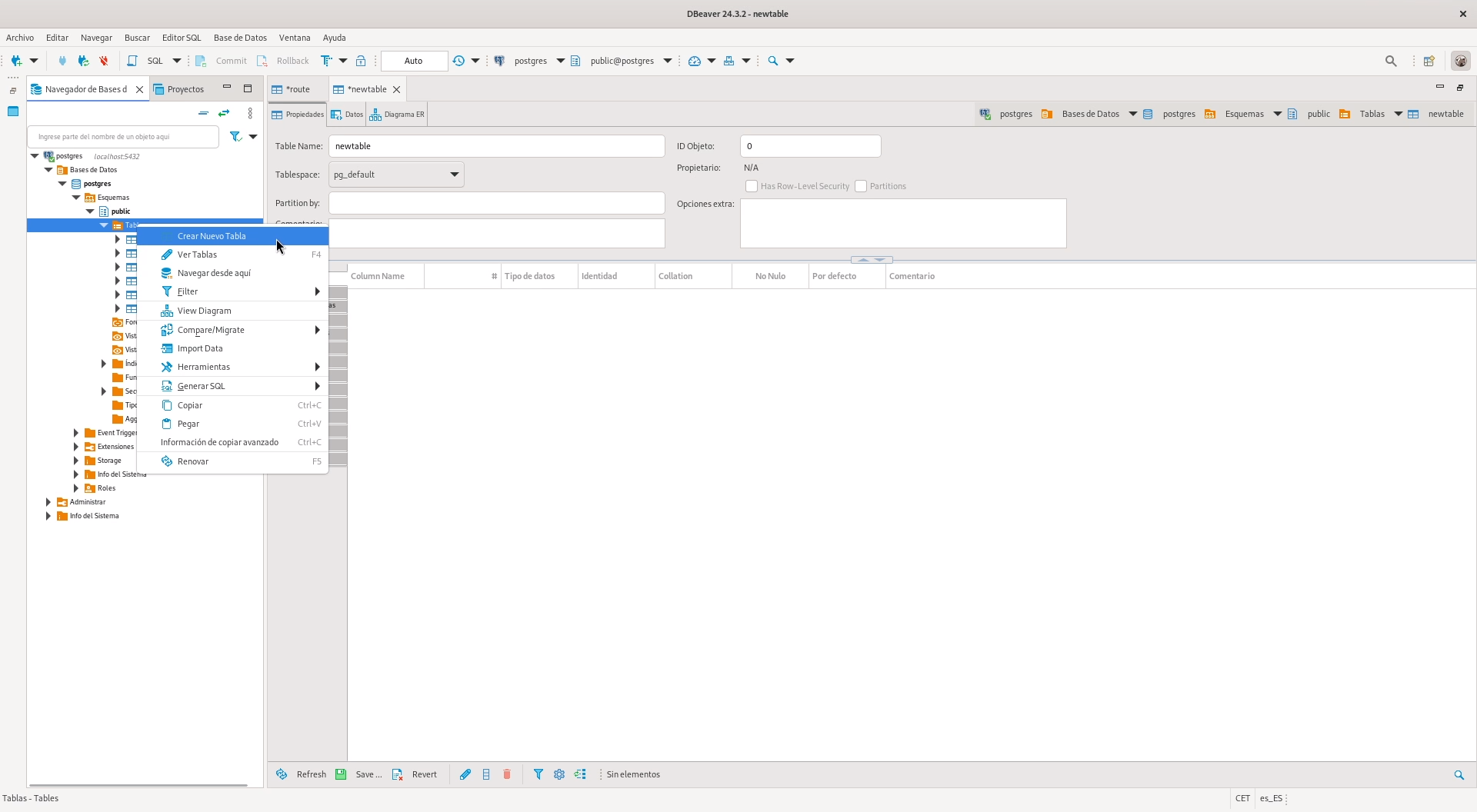
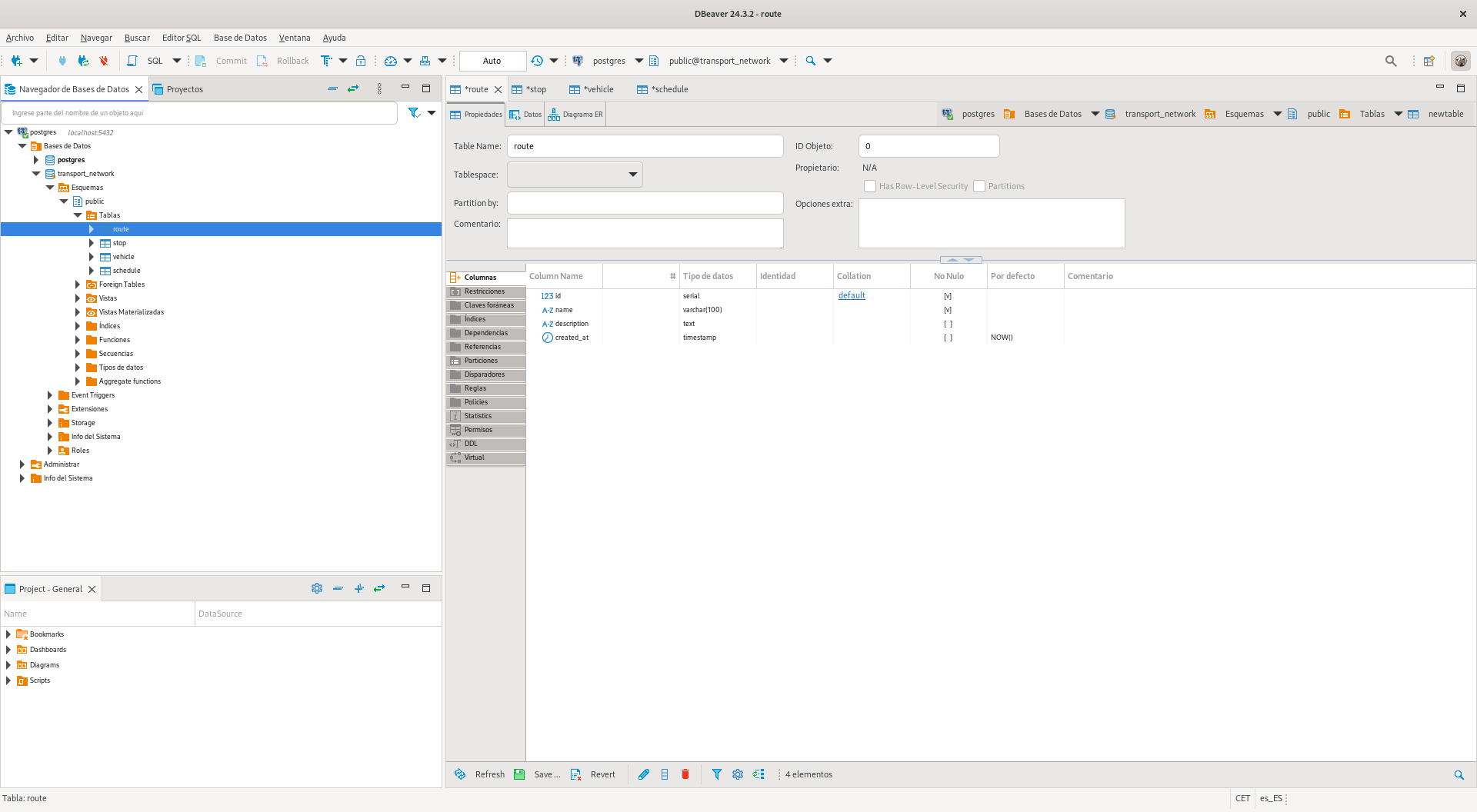
The model consists of four main tables: Route, Stop, Vehicle, and Schedule. Each table has primary keys and
well-defined relationships to ensure referential integrity. You can open the table creation dialog in DBeaver by
right-clicking on the relevant section in the navigation tree.
| Field | Data Type | Constraints | Description |
|---|---|---|---|
| id | SERIAL | PRIMARY KEY | Unique identifier for the route |
| name | VARCHAR(100) | NOT NULL | Name of the route |
| description | TEXT | NULL | Description of the route |
| created_at | TIMESTAMP | DEFAULT NOW() | Route creation date |
| Field | Data Type | Constraints | Description |
|---|---|---|---|
| id | SERIAL | PRIMARY KEY | Unique identifier for the stop |
| name | VARCHAR(100) | NOT NULL | Name of the stop |
| created_at | TIMESTAMP | DEFAULT NOW() | Stop creation date |
| Field | Data Type | Constraints | Description |
|---|---|---|---|
| id | SERIAL | PRIMARY KEY | Unique identifier for the vehicle |
| plate_number | VARCHAR(20) | UNIQUE NOT NULL | Vehicle license plate |
| capacity | INT | NOT NULL, CHECK (capacity > 0) | Maximum passenger capacity |
| route_id | INT | FOREIGN KEY REFERENCES route(id) | Assigned route for the vehicle |
| created_at | TIMESTAMP | DEFAULT NOW() | Vehicle record creation date |
| Field | Data Type | Constraints | Description |
|---|---|---|---|
| id | SERIAL | PRIMARY KEY | Unique identifier for the schedule |
| route_id | INT | NOT NULL, FOREIGN KEY REFERENCES route(id) ON DELETE CASCADE | Route for the schedule |
| stop_id | INT | NOT NULL, FOREIGN KEY REFERENCES stop(id) ON DELETE CASCADE | Stop for the schedule |
| vehicle_id | INT | FOREIGN KEY REFERENCES vehicle(id) ON DELETE SET NULL | Assigned vehicle for the schedule |
| scheduled_time | TIMESTAMP | NOT NULL | Scheduled time |
Route ↔ Stop: A route can include multiple stops.Route ↔ Vehicle: A route can have several assigned vehicles.Schedule manages the relationship between routes and stops, adding context with timing and vehicles.In PostgreSQL, the SERIAL data type is commonly used to define columns that serve as unique identifiers or primary
keys in a table. This data type simplifies the creation of auto-increment sequences, automatically generating values for
these columns whenever new records are inserted.
When you define a column as SERIAL, PostgreSQL automatically performs three actions:
Unlike other systems such as MySQL, where auto-increment functionality is directly tied to the column, PostgreSQL
creates an independent sequence that allows for greater flexibility. This sequence can be customized, reused across
multiple tables, or adjusted to set an initial value (START WITH) or increment (INCREMENT BY). Additionally,
PostgreSQL provides variants such as SMALLSERIAL, SERIAL, and BIGSERIAL, which correspond to the data types
SMALLINT, INTEGER, and BIGINT, respectively.
So far, we’ve explored how to design and work with a relational database in PostgreSQL, applying fundamental concepts
such as table creation, relationships, and the use of data types like SERIAL. This knowledge provides an excellent
foundation for further exploration and experimentation with this powerful database management system.
PostgreSQL stands out not only for its robustness and flexibility but also for its impressive range of advanced features that set it apart from other relational database systems. Some of these features include:
JSON and JSONB: The ability to store and query data in JSON format makes PostgreSQL ideal for modern applications
that handle semi-structured data. Its JSONB (binary JSON) variant further optimizes searches and operations on this
type of data.
Extensions: One of PostgreSQL’s unique strengths is its extension system, which allows you to expand its capabilities to meet specific project needs. Popular extensions like PostGIS (for geospatial data) or **pg_trgm ** (for similarity-based text searches) make PostgreSQL extremely versatile.
Advanced Functions: PostgreSQL enables the creation of custom functions and triggers, allowing you to automate processes and execute business logic directly within the database.
Concurrency Support: Thanks to its Multi-Version Concurrency Control (MVCC) model, PostgreSQL ensures consistent transactions even in environments with multiple users.
While we won’t dive deeper into these features in this article, exploring them can unlock a world of possibilities for your projects. As you continue practicing with the concepts covered in this series, we encourage you to learn more about the features that make PostgreSQL such a special tool. In future articles, we’ll delve deeper into these and other advanced PostgreSQL capabilities.
Keep learning and exploring! PostgreSQL has so much more to offer, but most importantly, Happy Coding!
That may interest you
In the previous chapter, we reviewed the origins and fundamentals of databases. We took a brief …
read moreToday we will talk about databases, which are often the backbone of modern computer systems, …
read moreGraphQL is an open source query and data manipulation language for new or existing data. It was …
read more