
Docker Compose for container management
Having explored the fundamentals of Docker and its power to deploy encapsulated applications, we now …
read moreToday we will talk about databases, which are often the backbone of modern computer systems, powering everything from business applications to social networks and e-commerce systems. Although we take their existence for granted today, database technology has not always been as advanced and accessible as it is now. In fact, the first data storage systems were developed in the 1960s, when the growing needs of organizations began to exceed the capabilities of traditional paper-based filing systems and other physical storage methods. As companies grew and the volume of information they needed to manage increased, the need for a digital solution became evident—one that would allow for the organization, storage, and rapid access to large amounts of data.
In its early stages, database systems were structured hierarchically or in networks, allowing data to be organized in tree or graph structures. Although these architectures were a significant advancement at the time, they also had important limitations, especially when it came to handling complex data and performing efficient queries. In a hierarchical system, data was stored in a tree structure, where each record had a single “parent,” which limited flexibility. On the other hand, networked database systems allowed for more complex relationships between data but were still difficult to implement and maintain, often requiring specific programming for each application.
This context of innovation and technical limitations motivated Edgar F. Codd, a computer scientist at IBM, to propose a new model for data storage and management in 1970, known as the “Relational Model.” Codd devised a system in which data could be stored in tables, allowing for access and manipulation through a query language that would later evolve into SQL (Structured Query Language). The relational model not only made it possible to efficiently store and access large volumes of information but also introduced unprecedented flexibility for complex queries. This paradigm shift drove the growth of databases as we know them today, laying the foundation for the development of database management systems (DBMS), which are still widely used today.
The introduction of the relational model revolutionized many industries, enabling the creation of more sophisticated business applications and promoting data-driven decision-making. Relational databases quickly became the standard for data storage and management, with their use spreading from banking and finance to logistics and retail. With the advent of database management systems such as IBM DB2, Oracle, and later, MySQL (MariaDB) and PostgreSQL, among others, companies gained access to powerful tools that allowed them to efficiently organize and analyze their data, enabling new capabilities to manage large-scale operations and processes.
As data continues to grow in volume and complexity, relational databases remain a central technology. However, new solutions have also emerged, such as NoSQL databases, which address specific needs that traditional relational systems do not always cover. Additionally, it is common for tools like Excel to be used informally as databases. Although Excel is not a database in the strict sense, its ease of use and tabular structure allow many users to store and organize data in a basic way. This phenomenon also occurs with tools like Access, which, while a more complete database management system, still does not offer the power and scalability of a full-fledged relational database management system.
As data continues to grow in volume and complexity, relational databases remain a key technology. However, more modern solutions have now emerged that meet the demands of artificial intelligence, real-time analysis, and the management of unstructured data, such as NoSQL databases, which address specific needs that traditional relational systems do not always cover.
Relational databases store information in structured tables with rows and columns, allowing for complex relationships between data. Based on the relational model proposed by Edgar F. Codd, their structure relies on the use of primary and foreign keys to link data across tables. This type of database is ideal for applications where data integrity and transactions are essential, such as financial systems, business management, or any application requiring ACID (Atomicity, Consistency, Isolation, Durability) properties.
Examples: Microsoft SQL (MSSQL), MySQL, PostgreSQL, Oracle.
Document databases are a type of NoSQL database that store data in documents, typically in JSON or BSON format. These documents can contain both structured and unstructured data and, unlike relational databases, do not require a fixed schema. This provides great flexibility, especially for handling dynamic data. Document databases are suitable for applications that require fast access to large volumes of unstructured data, such as content applications or e-commerce systems.
Examples: MongoDB, Cassandra, CouchDB, Firebase Realtime Database.
In-memory databases store data directly in RAM instead of on disks, allowing much faster access. They are ideal for applications that require high processing speed, such as online games, financial transaction systems, and real-time analytics. However, due to their dependence on RAM, they may have storage limitations compared to disk-based databases.
Graph databases store information in nodes and edges, making them ideal for representing complex relationships between entities. This type of database is particularly useful in applications where connections between data are as important as the data itself. A typical use of graph databases is in social networks, where relationships between users can be represented, or in recommendation systems and fraud analysis.
Examples: Neo4j, Amazon Neptune, ArangoDB.
There are other types of databases, such as time series databases, search databases, and columnar databases, each designed to meet specific performance needs. However, these are not the most common, so they will not be covered in depth in this series. We will focus on types of relational databases that are widely used today and that pose the most challenges when defining their structure.
Relational databases are probably the most widely used and studied type of database in the world of computing. Developed
in the 1970s by Edgar F. Codd, these databases are based on a structured model of interrelated tables, in which each
table represents an entity or concept (such as Customers or Products). The strength of relational databases lies in
their ability to maintain data integrity and consistency through normalization rules and constraints.
In a relational database, data is organized into tables composed of rows and columns. Each row represents a unique record (such as a specific customer), and each column represents an attribute of that record (such as the customer’s name or address). These tables can be related to each other through primary keys and foreign keys, allowing data to be linked and queried across multiple tables efficiently.
For example, an Orders table could be linked to a Customers table through a foreign key that stores the unique
identifier of the customer who placed each order. This structure provides great flexibility for performing queries and
retrieving complex information in a single operation. We will see a more detailed example below.
Referential integrity: one of the main peculiarities of relational databases is their ability to maintain data integrity through key constraints. Referential integrity ensures that relationships between tables are valid; that is, each foreign key in a table corresponds to an existing record in the referenced table. This prevents, for example, orders from being assigned to nonexistent customers.
ACID: relational databases usually adhere to ACID properties: atomicity, consistency, isolation, and durability. These properties are essential in applications where it is critical to ensure that transactions (such as payments or records) complete correctly.
SQL as a query language: relational databases use SQL (Structured Query Language) and its variants to define, manipulate, and query data. This enables complex queries using selection, join, and filter operators, offering a powerful and flexible syntax for data extraction. Additionally, SQL has evolved to support advanced features such as aggregations, subqueries, and stored procedures.
Data integrity: ensures that data is consistent and accurate through integrity constraints (such as primary keys, foreign keys, and uniqueness rules). For example, in a banking system, financial transactions rely on data integrity to ensure that account balances are accurate and there is no duplication of transactions.
Ability to perform complex queries: enables advanced and complex queries using SQL, making it easier to extract valuable information. For example, in an e-commerce company, analysts can use SQL to obtain detailed information, such as the average monthly spending of customers or the inventory of best-selling products. The ability to perform joins between multiple tables allows these systems to respond to complex queries quickly and accurately.
Vertical scalability for large volumes of data: designed to handle large amounts of data and scale vertically ( i.e., with more powerful hardware). In large organizations, such as a hospital that stores millions of medical records, a relational database can be managed on a high-performance server that allows for efficient processing, storage, and retrieval of massive amounts of data, ensuring fast access to patient information.
Concurrent access and user control: multiple users can access and manipulate data simultaneously without conflicts, thanks to concurrency control and permission mechanisms. For example, in a project management system, several employees can update real-time information on the status of different tasks without data corruption. Additionally, the administrator can set access permissions, ensuring that only authorized users can view or modify sensitive data.
Widely adopted and compatible standard: SQL is a widely accepted and compatible standard, which facilitates data migration and interoperability between different relational database systems. For example, a company that decides to switch its data management system from MySQL to PostgreSQL can migrate data and queries relatively easily due to SQL compatibility between these platforms. This standard also enables developers and analysts to adapt quickly to new systems without the need to relearn a different query language.
Even with all their many advantages, relational databases also have some limitations. For example:
Limited scalability: they are often designed for vertical scaling, which involves increasing the capacity of a single server to handle more data or users. This can be costly and complicated compared to NoSQL systems, which allow for easier horizontal scaling by adding multiple servers.
Rigid schema: the data structure is rigid and requires a predefined schema. This means that structural changes, such as adding new columns or modifying data types, can be complex and may require downtime. This structured design limits adaptability in environments where data changes rapidly.
Low performance with large volumes of unstructured data: they are not optimized for handling large volumes of unstructured data (such as free text, multimedia, or IoT-generated data), which can significantly impact performance in these types of applications. NoSQL databases are often more suitable for these cases.
High maintenance load: they require constant administration to ensure performance, security, and data integrity. Configurations such as indexes, permissions, and backups need regular management, which implies maintenance costs and specialized technical resources.
Complexity in distributed queries: performing distributed queries and transactions across multiple relational databases is complicated and can degrade performance. In distributed applications or high-availability systems, effectively managing distributed transactions is more complex and requires advanced configurations or even the use of external tools for synchronization and consistency.
Despite these limitations, relational databases remain a popular and effective choice for many business and mission-critical applications. Their ability to ensure data integrity, query flexibility, and extensive industry support make them a solid option for a wide variety of use cases. At their core, they use the relational model, which is defined by table structure and the relationships between them, organizing data in a way that is consistent and easily accessible.
Let’s now look at the fundamental concepts that underpin relational databases and how they are applied in practice.
Entities represent the main concepts on which information will be stored in the database. Each entity is defined in a table, which is the fundamental structure for organizing data. A table consists of rows and columns:
Customer
table, each row would contain data for an individual customer.name, address, or email in
the Customer table.There is much debate about whether tables should be named in plural or singular form; for example, using Customer or
Customers. The choice depends on the convention followed in the project or organization. Personally, I prefer to name
tables in singular because each row represents a single entity, not a set of them. This approach also facilitates
matching the table name with the class name when using an ORM (Object Relational Mapping), which adds consistency
and clarity to the code.
An ORM is a tool that maps database tables to objects in the code, making it easier to interact with the database from the application. Some popular ORMs include Hibernate for Java, Room for Android, Entity Framework for .NET, and Sequelize for Node.js.
It is essential to maintain consistency in naming conventions to avoid confusion, and, whenever possible, use names in English, as it is the “standard” language in programming and facilitates collaboration with developers worldwide if necessary.
One of the most important features of relational databases is the ability to establish relationships between different tables, which allows data to be organized and associated meaningfully. The most common relationships in a relational database include:
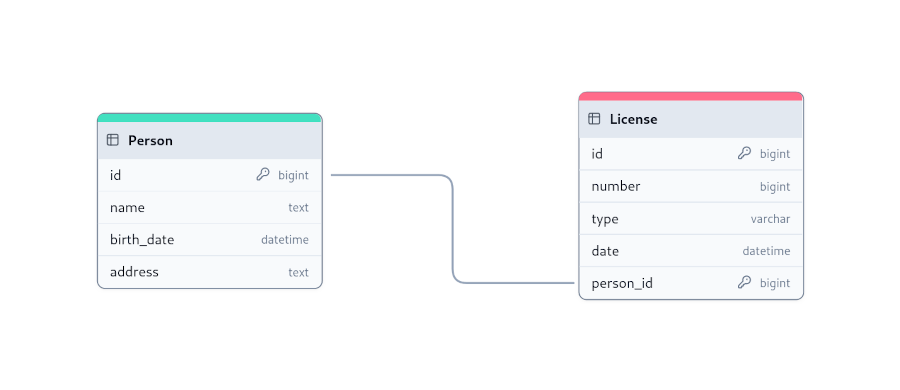
Person table and a License table, where each person has a single license, and each license is
associated with only one person. The foreign key in the referenced table is restricted to be unique, ensuring that the
relationship is one-to-one. Only one person can have a license, and only one license can belong to a person.Customer table) can place
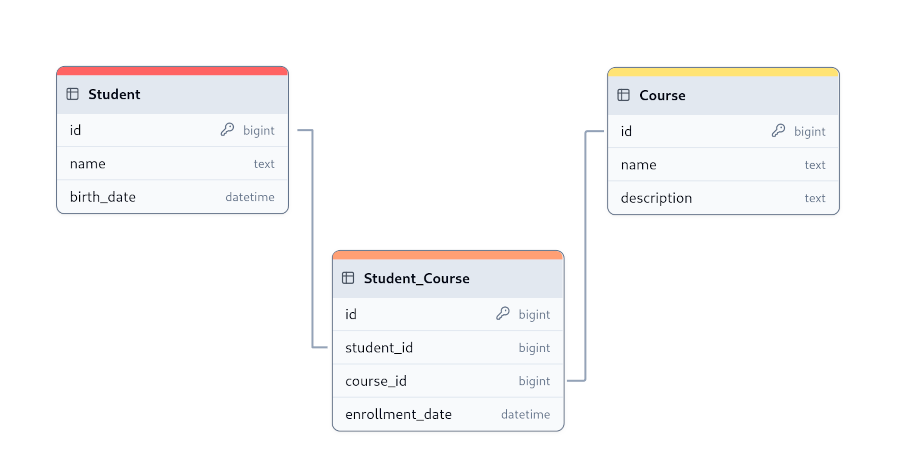
multiple orders (in the Order table), establishing a one-to-many relationship between Customer and Order.Student table and a Course table, where a student
can enroll in multiple courses, and a course can have multiple students. To manage these relationships, an
intermediate table, such as Student_Course, is created, containing references to the primary keys of Student and
Course.The examples presented here are simplified and will vary depending on the complexity of the application and data requirements. In general, each of the examples presented here would contain a larger number of fields and related tables. It is important to consider that the database structure should faithfully reflect the reality of the problem domain being addressed.
To manage these relationships, relational databases use primary keys and foreign keys:
Primary Key: a unique identifier for each record in a table. The primary key ensures that each row in a table is
unique. For example, in the Customer table, the id field can serve, and is often used, as the primary key.
Recently, the use of UUIDs (Universal Unique Identifiers) as primary keys has become popular, as they are globally
unique, do not rely on the database for generation, do not have the size limitations of integers, and offer better
privacy, though they may impact performance.
Foreign Key: a field in a table that references the primary key of another table, establishing a relationship
between the two. For example, in the Order table, the customer_id field can be a foreign key referencing the
primary key id in the Customer table, thus linking each order to the corresponding customer.
To ensure data quality and consistency, relational databases implement constraints and integrity rules:
Entity integrity: ensures that each table has a unique primary key, preventing duplicates and allowing for the unequivocal identification of each record.
Referential integrity: ensures that relationships between tables are valid; that is, foreign keys correspond to existing records in the referenced table. This rule prevents references to nonexistent records and ensures data coherence.
Uniqueness constraints: these constraints ensure that certain fields do not have duplicate values, as in the case of email addresses or identification numbers.
These basic elements make relational databases a robust and versatile tool for managing data in an organized, precise, and consistent manner. By understanding these fundamental concepts, developers can design relational databases that efficiently meet the requirements of their applications.
We have explored an introduction to databases, their evolution over time, and the key concepts underpinning relational databases. In future articles, we will delve into the more technical aspects of relational databases, such as table design and SQL queries, so you can start working with databases in your own projects. See you next time, and Happy Coding!
That may interest you
Having explored the fundamentals of Docker and its power to deploy encapsulated applications, we now …
read moreGraphQL is an open source query and data manipulation language for new or existing data. It was …
read moreIn any operating system, installing, updating, and removing software is a fundamental task. In …
read more