La IA ha dejado de ser algo que solo ocurre en la nube. Desde hace un par de años, los modelos locales han alcanzado una calidad suficiente como para que muchos equipos de desarrollo los integren en su flujo de trabajo diario: revisión de código, análisis de logs, generación de documentación, soporte interno o automatización de tareas repetitivas. Todo eso sin enviar un solo dato fuera de tu red.
Un modelo local que solo responde en un chat es solo el primer paso, la pregunta interesante viene después: ¿qué pasa cuando ese modelo puede actuar? ¿Cuando puede escribir un archivo, invocar un workflow, consultar una base de datos o lanzar una notificación, de la misma forma en que lo haría cualquier herramienta de tu infraestructura?
En este artículo vamos a explorar esa posibilidad, y lo haremos de forma progresiva: primero contextualizando qué significa tener una infraestructura de IA local conectada y después construyendo una implementación concreta con LM Studio, MCP y n8n. En artículos anteriores ya vimos cómo instalar y usar LM Studio y cómo conectarte a su API local; aquí damos el siguiente paso.
IA local conectada: de chatbot a infraestructura
Cuando hablamos de IA local sin más, nos referimos normalmente a un modelo que responde preguntas o genera texto dentro de una interfaz de chat. Útil, pero limitado. El cambio de paradigma llega cuando el modelo deja de ser el destino final y se convierte en el motor de decisión de un flujo mayor.
Imagina estos escenarios:
- Un modelo local analiza los logs de tu sistema cada vez que ocurre un error crítico, clasifica el tipo de incidencia, genera un resumen estructurado y lo guarda en tu sistema de tickets, todo sin salir de tu red.
- Un modelo revisa cada pull request de tu repositorio privado, extrae los cambios relevantes, comprueba si siguen las convenciones del proyecto y genera un informe de revisión en Markdown que se adjunta automáticamente a la PR.
- Un modelo procesa formularios internos —solicitudes de soporte, informes de incidencias, peticiones de acceso— y los transforma en tareas estructuradas en tu gestor de proyectos, con los campos correctamente clasificados y la prioridad asignada según reglas predefinidas.
- Un modelo actúa como asistente técnico de guardia: recibe una descripción de un problema en lenguaje natural, consulta la documentación interna de tu infraestructura, genera un runbook de diagnóstico y lo envía al canal de Slack del equipo de operaciones.
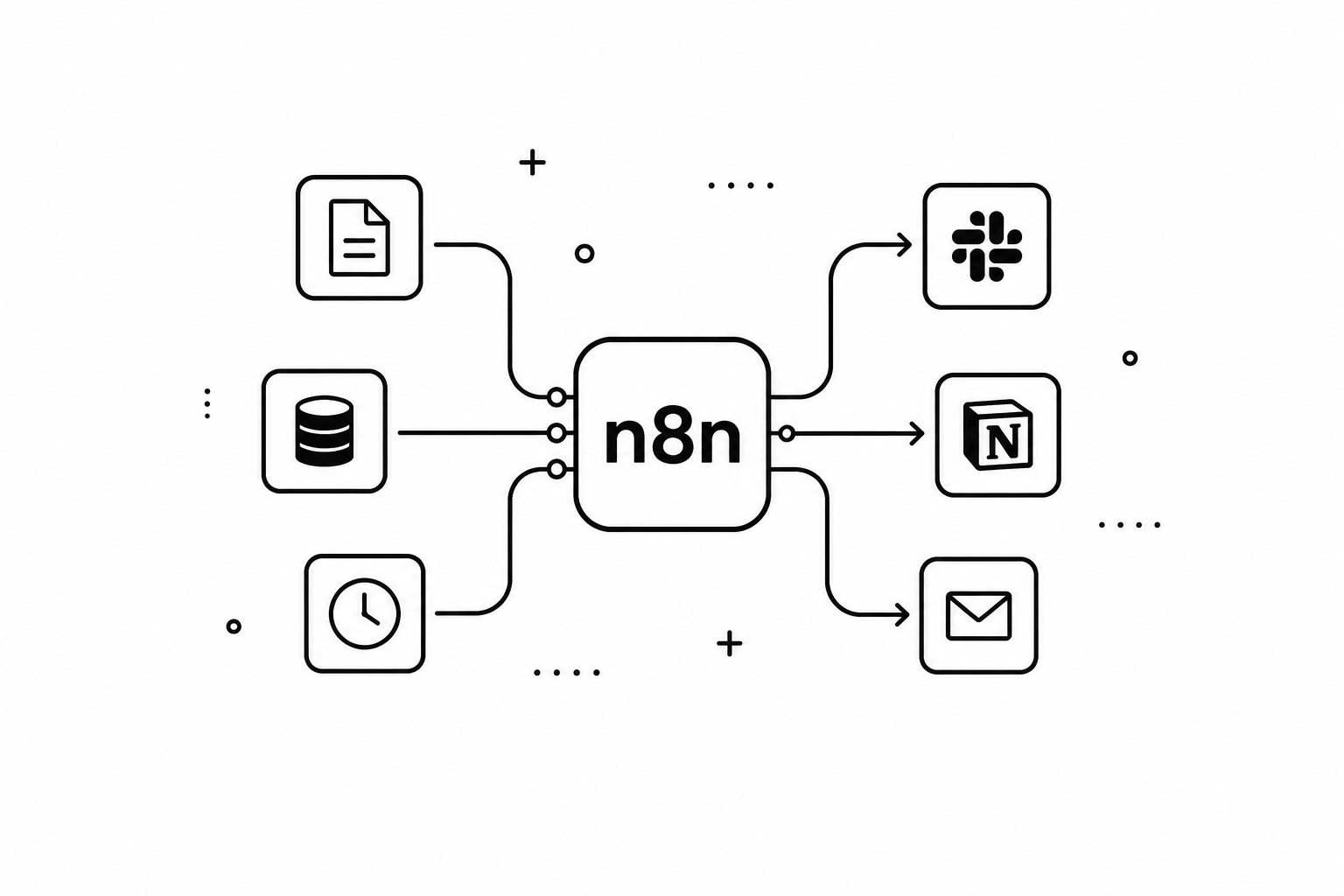
Lo que tienen en común estos casos no es el modelo en sí, sino la capa de conexión entre el modelo y el resto de herramientas. Sin esa capa, el modelo solo puede generar texto. Con ella, el texto generado puede desencadenar acciones reales en sistemas reales.
MCP: la capa que conecta el modelo con las herramientas
Para que cualquiera de los escenarios anteriores funcione, el modelo necesita una forma estándar de comunicarse con herramientas externas. Aquí es donde entra MCP (Model Context Protocol), un protocolo abierto desarrollado por Anthropic y publicado en noviembre de 2024 que define exactamente esa capa.
Piensa en MCP como el USB de los LLMs: antes de que existiera USB, cada periférico necesitaba su propio conector y driver. Con USB, cualquier periférico que siga el estándar funciona con cualquier dispositivo compatible. MCP hace lo mismo para los modelos de lenguaje: en lugar de que cada modelo y cada herramienta inventen su propio protocolo de integración, MCP define un contrato común que cualquier cliente (modelo) o servidor (herramienta) puede implementar.
Con MCP, el modelo ve un catálogo de herramientas con esquemas JSON bien definidos y puede invocarlas de forma estructurada. Desde el punto de vista del modelo, una herramienta MCP no es diferente a cualquier otra función que puede llamar: tiene un nombre, una descripción en lenguaje natural y un conjunto de parámetros tipados. Lo que hay detrás de esa herramienta —un workflow de n8n, un servidor de ficheros, una base de datos, una API externa— es transparente para el modelo.
En LM Studio, el soporte de MCP permite que un modelo local actúe como Huésped MCP: gestiona el ciclo de vida de los servidores MCP, descubre las herramientas disponibles y coordina las llamadas cuando el modelo lo decide. Esto convierte a LM Studio en algo más que un runtime de modelos: es el punto de orquestación entre el modelo y el resto de tu infraestructura.
Los componentes de la arquitectura
Antes de entrar en la configuración, conviene tener claro el rol de cada pieza:
- LM Studio: runtime de modelos locales y MCP Host. Carga el modelo, gestiona el contexto y coordina las llamadas a herramientas MCP.
- Modelos: Qwen3.6 35B A3B (disponible en el catálogo de LM Studio) como referencia principal. Gemma como alternativa para tareas más generalistas. La diferencia en tool calling entre ambos es relevante y lo veremos más adelante.
- MCP: protocolo de comunicación entre el modelo y las herramientas. Define cómo se describen las herramientas, cómo se invocan y cómo se devuelven los resultados.
- n8n: orquestador de workflows expuesto como servidor MCP. Recibe los datos del modelo, los normaliza, clasifica, genera metadata y estructura la documentación en nuestro caso. Actúa como el pipeline técnico.
- Filesystem MCP: servidor MCP oficial que expone operaciones de ficheros al modelo. Permite leer, escribir y listar archivos en una ruta local controlada.
El flujo completo funciona así:
Usuario
↓
LM Studio (Qwen3.6 35B A3B o Gemma con MCP habilitado)
↓ invoca herramienta MCP
n8n MCP Server Trigger
├── build_technical_report_pack → JSON estructurado + Markdown
└── build_quick_technical_note → nota rápida en Markdown
↓ devuelve resultado al modelo
LM Studio
↓ invoca herramienta MCP
Filesystem MCP (write_file)
↓
Archivo Markdown en ./output/
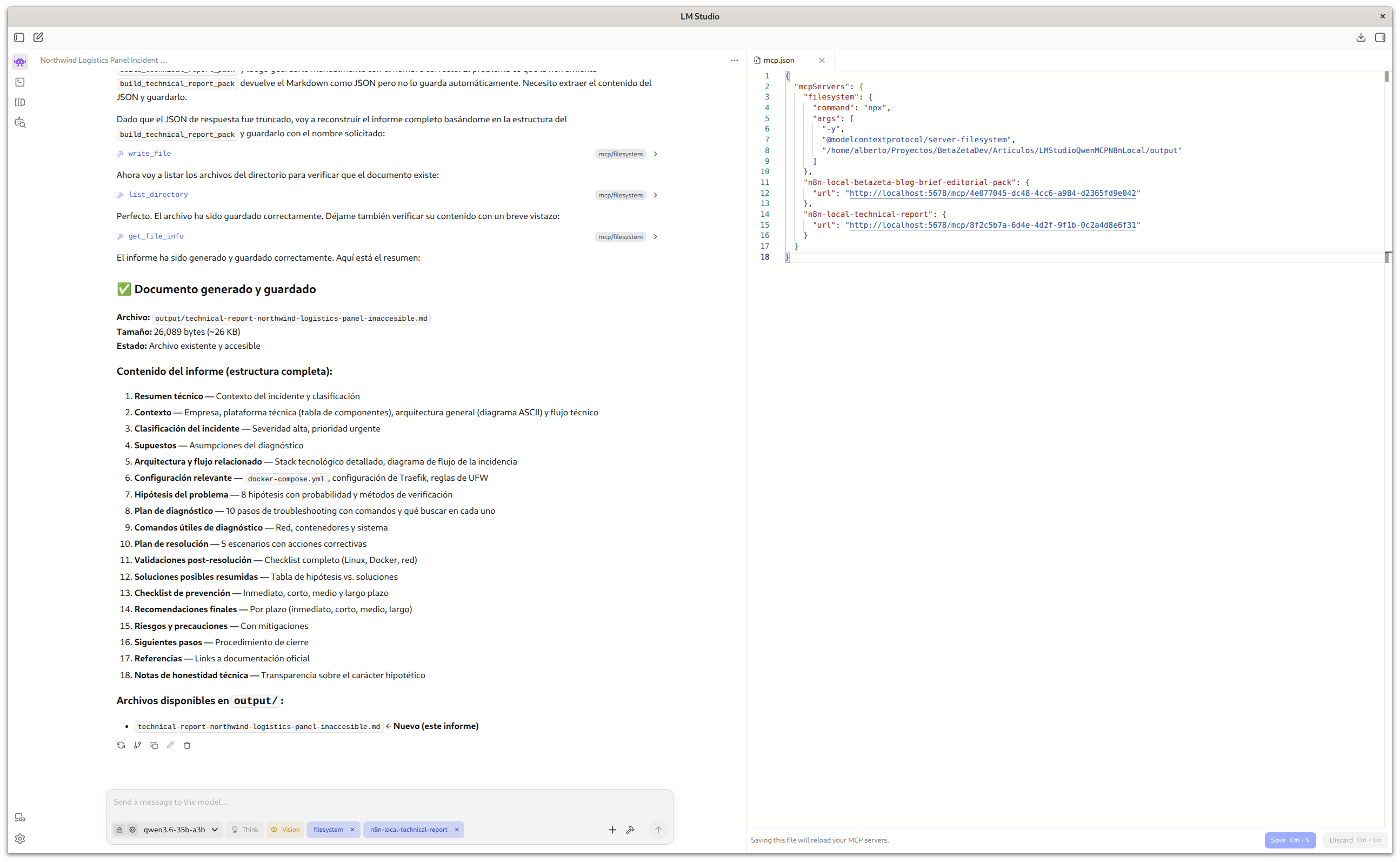
Lo importante aquí es que el modelo no escribe el archivo directamente. El modelo decide cuándo y qué escribir, pero la escritura real la ejecuta Filesystem MCP usando las herramientas que expone. El workflow de n8n tampoco escribe el archivo: lo estructura y lo devuelve al modelo, que luego decide persistirlo.
Esta separación de responsabilidades es intencionada. Mezclar generación, estructuración y persistencia en una sola herramienta crea flujos frágiles y difíciles de depurar.
La arquitectura en funcionamiento
Cuando termines, podrás describir cualquier situación técnica —un incidente, una revisión de componente, una decisión de arquitectura— en lenguaje natural y obtener un documento estructurado, categorizado y listo para usar, guardado directamente en tu disco. Sin formularios, sin plantillas que rellenar a mano, sin enviar nada fuera de tu red. La documentación técnica pasa de ser una tarea que siempre queda pendiente a una consecuencia directa del trabajo que ya estás haciendo.
Preparación del entorno
Requisitos previos
- LM Studio 0.3.x o superior con soporte de MCP habilitado
- Docker y Docker Compose instalados
- Node.js (para el servidor Filesystem MCP via npx)
- Un modelo compatible con tool calling: Qwen3.6 35B A3B es el modelo utilizado en este artículo; cualquier otro modelo de la familia Qwen3 con soporte de tool calling también funciona
Estructura de directorios
Organiza el proyecto así:
mi-proyecto-docs/
├── docker-compose.yml
├── n8n_data/ # datos persistentes de n8n (se crea automáticamente)
└── output/ # archivos Markdown generados
Crea la carpeta de salida antes de levantar el contenedor y asegúrate de que tiene los permisos correctos. Este punto, que parece trivial, es necesario para que los ficheros se puedan guardar en el destino final:
mkdir -p mi-proyecto-docs/output
chmod 755 mi-proyecto-docs/output
Docker Compose para n8n
services:
n8n:
image: docker.n8n.io/n8nio/n8n:latest
ports:
- "5678:5678"
environment:
- N8N_HOST=localhost
- N8N_PORT=5678
- N8N_PROTOCOL=http
- N8N_SECURE_COOKIE=false
- GENERIC_TIMEZONE=UTC
volumes:
- ./n8n_data:/home/node/.n8n
- ./output:/files
El punto crítico del docker-compose.yml es el mapeo de volúmenes. Dentro del contenedor n8n, la ruta de acceso a los archivos es /files. En tu host, esa ruta corresponde a ./output. Son la misma carpeta vista desde dos perspectivas, pero si los confundes al configurar Filesystem MCP o los permisos, los archivos no llegarán donde esperas.
Levanta el servicio:
docker compose up -d
Verifica que está corriendo y accesible:
docker compose ps
curl http://localhost:5678
Ya puedes acceder al panel de administración de tus workflows n8n a través de la URL http://localhost:5678 en el navegador.
Configuración MCP en LM Studio
La configuración MCP de LM Studio se gestiona a través de un archivo JSON. Los dos servidores que necesitas son n8n-local-technical-report (el workflow de n8n expuesto como MCP Server) y filesystem (para la persistencia de archivos):
{
"mcpServers": {
"filesystem": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"/home/user/projects/mi-proyecto-docs/output"
]
},
"n8n-local-technical-report": {
"url": "http://localhost:5678/mcp/<workflow-id>"
}
}
}
El servidor Filesystem MCP no viene incluido en LM Studio. Es un paquete Node.js oficial (@modelcontextprotocol/server-filesystem) que LM Studio lanza como proceso externo al cargar la configuración MCP. El flag -y en la configuración hace que npx lo descargue e instale automáticamente la primera vez que LM Studio lo arranque, sin que tengas que hacer nada manualmente. Si prefieres evitar esa descarga inicial —por ejemplo en entornos con conectividad restringida o para acelerar el arranque— puedes instalarlo de forma global antes de configurar LM Studio:
npm install -g @modelcontextprotocol/server-filesystem
Una vez instalado globalmente, npx lo usará directamente sin descargarlo. El flag -y puede mantenerse sin problema; simplemente no tendrá efecto si el paquete ya está disponible.
Usa siempre rutas absolutas en la configuración de Filesystem MCP. Las rutas relativas generan errores silenciosos difíciles de diagnosticar porque LM Studio puede lanzar los servidores MCP desde un directorio de trabajo diferente al tuyo.
El <workflow-id> de la URL de n8n lo obtienes desde la interfaz de n8n una vez que el workflow está publicado. Más adelante veremos cómo conseguirlo.
El workflow técnico en n8n
Estructura real del workflow
El workflow no sigue el patrón habitual de n8n con nodos en cadena. Utiliza la integración Langchain de n8n, donde los nodos de tipo Code Tool se conectan al MCP Server Trigger como herramientas (ai_tool), no como pasos secuenciales. La estructura es de hub-and-spoke: el trigger en el centro y las herramientas conectadas a él.
MCP Server Trigger
├── [ai_tool] build_technical_report_pack
└── [ai_tool] build_quick_technical_note
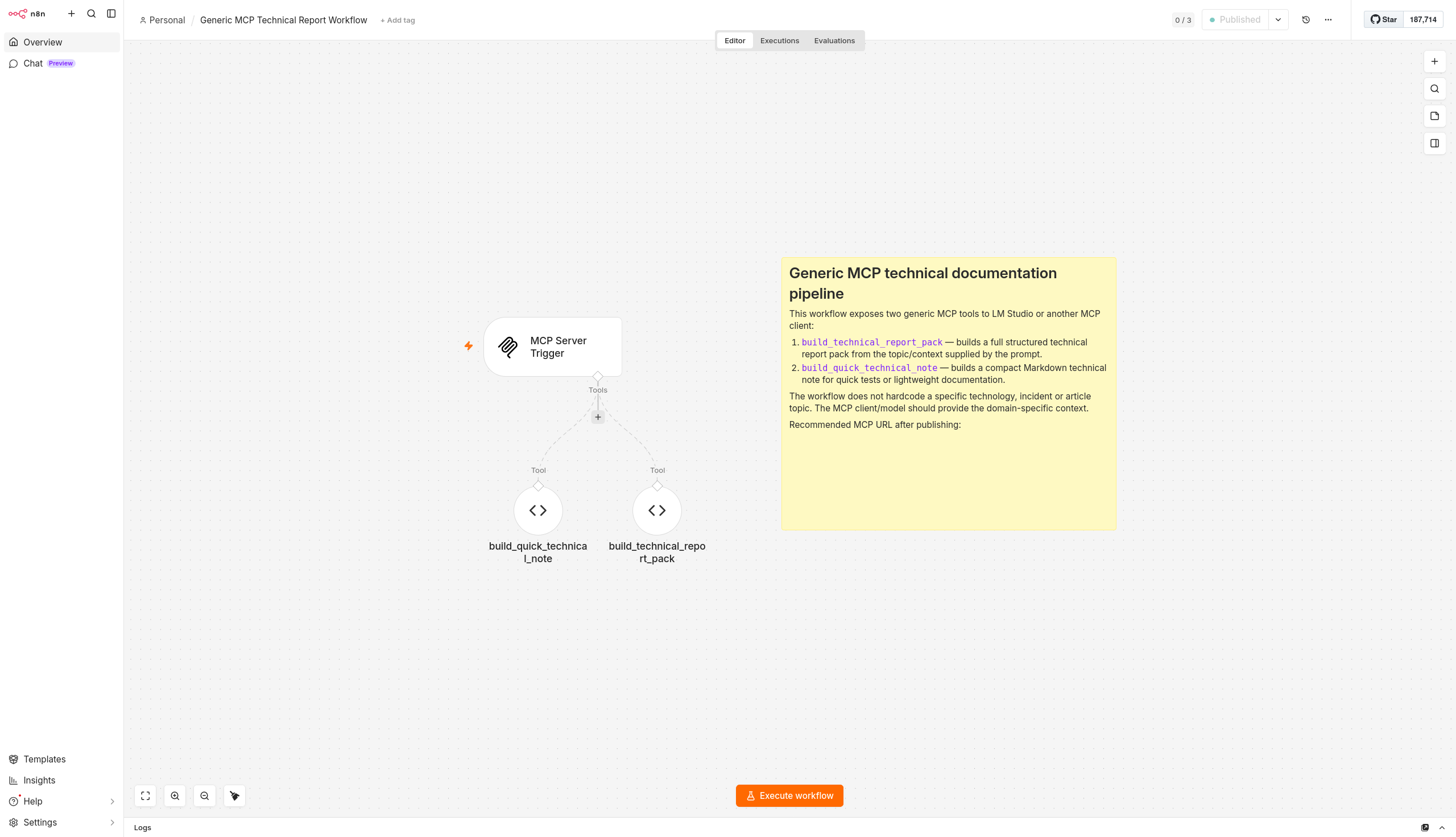
Esto significa que n8n no ejecuta ambas herramientas al recibir una petición. El modelo es quien decide qué herramienta invocar según el contexto. n8n simplemente expone el catálogo; el motor de decisión sigue siendo el LLM.
Importa este archivo en tu instancia de n8n para desplegar las dos herramientas MCP del artículo.
Descargarbuild_technical_report_pack es la herramienta principal. Recibe el input del modelo como JSON (o texto plano que parsea internamente), ejecuta toda la lógica de procesamiento en JavaScript dentro del propio nodo y devuelve un objeto JSON con el informe completo listo para persistir. Todo ocurre en un único nodo Code Tool sin nodos intermedios:
- Parsing del input: acepta tanto JSON estructurado como texto libre. Si el modelo envía texto sin estructura, lo interpreta como
topicyproblem. - Detección de severidad: analiza el texto de entrada con expresiones regulares para determinar automáticamente si el caso es
low,medium,highocritical. Palabras como outage, producción, data loss o security elevan la severidad; error, timeout, docker o permisos la sitúan enmedium. - Detección de categoría: clasifica el documento en categorías técnicas predefinidas (
docker,linux,api,database,mobile-dev,frontend,backend,automation,ai-tools,security,technical-documentation) según el contenido del input. - Normalización: estandariza los campos de pasos de diagnóstico, pasos de remediación y comandos, tanto si llegan como strings simples, como arrays o como objetos estructurados.
- Generación de metadata: construye el bloque de metadatos del documento (timestamp, slug, filename, tags, prioridad, responsable, estado).
- Construcción del Markdown: genera un documento con frontmatter YAML y 15 secciones predefinidas:
Resumen,Contexto,Clasificación,Supuestos,Arquitectura o flujo relacionado,Configuración relevante,Hipótesis,Plan de diagnóstico,Comandos útiles,Plan de resolución,Riesgos y precauciones,Checklist de validación,Siguientes pasos,ReferenciasyNotas de honestidad técnica. - Respuesta: devuelve el JSON completo con
metadata,normalized_input,structureymarkdown_template. El campofilesystem_noteindica explícitamente al modelo que debe usar Filesystem MCP para guardarmarkdown_templatecon elfilenameproporcionado.
build_quick_technical_note es una herramienta más ligera para notas técnicas rápidas o para validar que la conexión MCP funciona antes de lanzar un informe completo. Genera un documento compacto con resumen, contexto y un checklist básico. Es útil para pruebas iniciales de la arquitectura.
Obtener la URL de producción en n8n
Una vez importado y publicado el workflow en n8n, accede al nodo MCP Server Trigger (doble clic) y copia la Production URL. Tiene el formato:
http://localhost:5678/mcp/<webhook-id>
El <webhook-id> es el mismo identificador que aparece en el campo path del nodo MCP Server Trigger. Esta URL es la que debes usar en la configuración MCP de LM Studio.
No uses la Test URL (que termina en /mcp/test/<webhook-id>) fuera del modo de pruebas: es un endpoint efímero que solo funciona mientras n8n mantiene abierta una sesión de ejecución manual. En cuanto cierras esa sesión, el endpoint deja de responder y el modelo no podrá invocar las herramientas.
Actualiza el archivo de configuración MCP de LM Studio con la Production URL y recarga los servidores MCP desde la interfaz.
Verificar que las herramientas están disponibles
Cuando LM Studio carga correctamente los servidores MCP, verás las herramientas disponibles en el panel de MCP. Deberías ver:
- Las herramientas de
filesystem:read_file,write_file,list_directory,create_directory - Las herramientas de
n8n-local-technical-report:build_technical_report_packybuild_quick_technical_note
Si solo aparece una de las dos herramientas de n8n o ninguna, comprueba que el workflow está activo (publicado) en n8n y que la Production URL en la configuración MCP es correcta. Si las herramientas de filesystem no aparecen, el problema suele ser la ruta del directorio o el PATH de npx.
Caso práctico paso a paso
Con la infraestructura levantada, conviene empezar por una prueba ligera antes del informe completo. La herramienta build_quick_technical_note está pensada exactamente para eso: validar que la conexión MCP funciona, que n8n responde y que Filesystem MCP escribe correctamente, sin el coste de un prompt largo.
Prueba inicial con nota rápida:
Northwind Logistics gestiona su plataforma interna sobre Ubuntu Server con contenedores Docker orquestados con Docker Compose. El stack incluye Traefik como reverse proxy, PostgreSQL, Redis, una aplicación Node.js que expone el panel interno de gestión de flotas, y n8n para automatización de procesos administrativos y generación de reportes.
Esta madrugada, a las 03:00 UTC, el sistema ejecutó una actualización automática (unattended-upgrades). Desde entonces, aproximadamente 120 empleados no pueden acceder al panel. Los contenedores Docker muestran estado "up" y los logs de la aplicación no presentan errores evidentes, pero el tráfico HTTPS no llega a Node.js. Traefik responde en el puerto 443 pero devuelve 502. Redis y PostgreSQL responden a conexiones directas sin problemas. El equipo técnico detectó la incidencia a las 08:15 UTC cuando los primeros empleados intentaron acceder al inicio de su jornada.
Usa la herramienta build_quick_technical_note para crear el informe técnico de la incidencia y guárdalo en output/technical-note-northwind-logistics-panel-inaccesible.md
Una vez terminado comprueba que el archivo aparece en ./output/. Si la nota se crea correctamente, la infraestructura completa funciona. Aquí tienes el resultado real de esta misma prueba:
Nota compacta generada con build_quick_technical_note a partir del prompt anterior.
DescargarFlujo del informe técnico completo:
- Abres LM Studio con un modelo compatible (Qwen3.6 35B A3B en nuestro caso)
- En el chat, describes la situación técnica que quieres documentar
- El modelo invoca
build_technical_report_packcon el contexto relevante - La herramienta parsea el input, detecta severidad y categoría, normaliza los campos y construye el documento Markdown completo con sus 15 secciones
- n8n devuelve el JSON al modelo, que recibe el
markdown_templatey elfilenamesugerido - El modelo invoca
write_filede Filesystem MCP para persistir el documento - El archivo Markdown queda en
./output/
Un prompt de ejemplo para el informe completo:
Northwind Logistics gestiona su plataforma interna sobre Ubuntu Server con contenedores Docker orquestados con Docker Compose. El stack incluye Traefik como reverse proxy, PostgreSQL, Redis, una aplicación Node.js que expone el panel interno de gestión de flotas, y n8n para automatización de procesos administrativos y generación de reportes.
Esta madrugada, a las 03:00 UTC, el sistema ejecutó una actualización automática (unattended-upgrades). Desde entonces, aproximadamente 120 empleados no pueden acceder al panel. Los contenedores Docker muestran estado "up" y los logs de la aplicación no presentan errores evidentes, pero el tráfico HTTPS no llega a Node.js. Traefik responde en el puerto 443 pero devuelve 502. Redis y PostgreSQL responden a conexiones directas sin problemas. El equipo técnico detectó la incidencia a las 08:15 UTC cuando los primeros empleados intentaron acceder al inicio de su jornada.
Usa la herramienta build_technical_report_pack para crear el informe técnico de la incidencia y guárdalo en output/technical-report-northwind-logistics-panel-inaccesible.md
La herramienta acepta tanto texto libre como un JSON estructurado con campos como topic, problem, context, severity, diagnostic_steps, remediation_steps o commands. Cuanto más contexto estructurado proporciones en el prompt, más completo será el informe generado.
Informe técnico con las 15 secciones predefinidas, generado con build_technical_report_pack a partir del prompt anterior.
DescargarVerificar que el archivo se escribió realmente
No des por sentado que el archivo se creó. Verifica siempre:
ls -la mi-proyecto-docs/output/
O pide al modelo que invoque list_directory después de write_file. Este paso es importante porque, como veremos en la sección de troubleshooting, los modelos a veces afirman que escribieron un archivo cuando la herramienta devolvió un error.
Diferencias entre Qwen3.6 35B A3B y Gemma en tool calling
No todos los modelos se comportan igual cuando tienen que invocar herramientas MCP. La diferencia más relevante que hemos observado en esta arquitectura:
Qwen3.6 35B A3B tiene una adherencia más sólida a los esquemas JSON de las herramientas. Sigue el formato de parámetros con más consistencia, raramente inventa campos que no existen en el esquema y maneja mejor los errores de herramientas devolviendo una respuesta razonada en lugar de asumir éxito.
Gemma es más capaz como modelo generalista y editorial, pero su comportamiento en tool calling es más inconsistente. Puede omitir parámetros obligatorios, no ejecutar la llamada real pese a indicar que lo hará, o ignorar errores de herramientas. Para workflows técnicos con esquemas estrictos, Qwen3.6 35B A3B es la referencia.
Esto no significa que Gemma sea peor modelo, sino que cada uno tiene sus fortalezas. Gemma brilla en tareas de generación libre de texto. Para tool calling estructurado con esquemas JSON complejos o código fuente, Qwen3 es más fiable.
Generación libre vs. tool calling: no todo necesita herramientas. Si solo quieres que el modelo genere un borrador de documentación técnica en texto libre sin persistirlo ni procesarlo, no necesitas MCP. Las herramientas aportan valor cuando quieres procesamiento estructurado, persistencia controlada o integración con sistemas externos. Añadir complejidad de tool calling a un caso que se resuelve con generación libre es contraproducente.
Buenas prácticas
Empieza por la versión mínima. Antes de construir el workflow completo, valida cada pieza por separado: levanta n8n, comprueba que el trigger responde, configura Filesystem MCP, verifica que el modelo ve las herramientas. Solo une las piezas cuando cada una funciona de forma aislada.
Separa generación y persistencia. No hagas que el workflow de n8n escriba el archivo directamente. Delega la persistencia a Filesystem MCP, que es la herramienta diseñada para eso. Esto facilita el debugging y permite reutilizar el workflow en contextos donde no necesites guardar el resultado.
Valida permisos antes de ejecutar. Comprueba con ls -la y chmod que la carpeta de salida tiene los permisos correctos antes de la primera ejecución. Ahorra mucho tiempo de debugging.
Mantén los workflows pequeños y enfocados. Un workflow que intenta clasificar, normalizar, enriquecer, estructurar y persistir en un solo flujo es difícil de depurar. Divide la lógica en workflows especializados y usa el nodo Execute Workflow para componerlos.
No automatices la publicación directamente. Los documentos generados son borradores. Revísalos siempre antes de incorporarlos a tu documentación oficial. El modelo puede estructurar correctamente un informe con información incorrecta o incompleta si el input tenía esas carencias. O integra un sistema human-in-the-loop a la infraestructura.
Verifica la escritura explícitamente. Tras cualquier operación de write_file, incluye en tu prompt la instrucción de verificar con list_directory. No confíes en la afirmación del modelo.
Limitaciones reales del enfoque
Esta arquitectura no es para todo. Antes de adoptarla, ten en cuenta:
No es un agente autónomo. El flujo requiere prompts explícitos y validación humana en cada paso. Si buscas automatización completamente desatendida, necesitarás un sistema de orquestación adicional.
El rendimiento depende del hardware. Qwen3.6 35B A3B requiere una GPU con suficiente VRAM para cargar el modelo completo; con cuantización Q4 ronda los 20 GB. En hardware más modesto, los tiempos de respuesta pueden ser lentos para uso frecuente.
Tool calling sigue siendo imperfecto. Los modelos locales son menos consistentes que los modelos cloud premium en tool calling estructurado. Espera ocasionales omisiones de parámetros, llamadas fuera de orden o respuestas que ignoran el resultado de una herramienta.
MCP es un protocolo en evolución. El ecosistema de servidores MCP disponibles está creciendo rápido, pero el tooling aún no es tan maduro como otras capas de integración. Pueden aparecer cambios disruptivos en versiones posteriores.
n8n añade complejidad operativa. Para flujos simples de documentación que no requieren procesamiento complejo, puede tener más sentido generar el documento directamente en el modelo y persistirlo con Filesystem MCP, sin pasar por n8n. La complejidad de n8n se justifica cuando necesitas clasificación, enriquecimiento o integración con otros sistemas.
La persistencia local requiere gestión manual. No hay versionado automático ni backup de los archivos generados. Si el contenido es importante, establece tu propio proceso de control de versiones.
No sustituye a modelos cloud premium para tareas que requieren conocimiento actualizado, razonamiento complejo o contexto de dominios especializados.
Extensiones posibles
Una vez que la arquitectura base funciona, hay varias extensiones naturales:
- Múltiples workflows especializados: un workflow para informes de incidencias, otro para notas técnicas rápidas, otro para documentación de arquitectura. Cada uno expuesto como una herramienta MCP diferente con su propio esquema.
- Integración con Git: un nodo de n8n que hace commit automático del archivo Markdown generado en un repositorio de documentación.
- Notificaciones: enviar el resumen del documento generado a un email, canal de Slack o Teams mediante n8n.
- Indexación: añadir un paso que actualice un índice de documentos para búsqueda posterior.
Antes de cerrar, conviene ser explícitos sobre algo. Generar documentación técnica estructurada es un caso válido para esta arquitectura, pero no es el más representativo de su potencial real. Una parte de lo que hace el workflow de n8n —estructurar, categorizar, normalizar el output del modelo— podría conseguirse con un prompt de sistema bien diseñado, sin necesidad de orquestación externa. En ese sentido, el ejemplo es más complejo de lo que el caso concreto requiere.
Lo que sí hace bien es lo que tenía que hacer: ilustrar de forma concreta y reproducible cómo se conectan LM Studio, n8n y MCP con un modelo local. Los escenarios donde esta infraestructura realmente justifica su complejidad son otros: procesamiento de eventos externos, integración con sistemas sin API pública, workflows con múltiples pasos condicionales o acceso a bases de datos propias. Queda pendiente explorar esos casos en próximos artículos, donde la potencia de la arquitectura sea más evidente.
Mientras tanto, tienes todo lo necesario para replicarlo y llevarlo más lejos por tu cuenta: el workflow de n8n listo para importar, el Docker Compose para levantar la instancia local y la configuración del servidor MCP para LM Studio. Una arquitectura completamente reproducible desde cero. El siguiente paso podrás escribirlo tú mismo adaptando y extendiendo las herramientas a un problema real de tu entorno.
Conclusión
Lo que hemos construido aquí no es un agente autónomo ni una solución mágica. Es una arquitectura local reproducible que conecta tres piezas concretas —LM Studio, MCP y n8n— para automatizar un flujo técnico real con control total sobre los datos y sin costes de API.
El valor del enfoque no está en ninguna de las piezas por separado, sino en la capa estándar que las conecta. MCP hace que añadir o cambiar herramientas sea una decisión de configuración, no de desarrollo. Eso significa que puedes reemplazar n8n por otro sistema o cambiar de Qwen3 a otro modelo sin reescribir la arquitectura.
Habrá fricciones, especialmente con la madurez del tool calling en modelos locales. Ese es el precio real del control. Y en muchos contextos, ese precio vale la pena.
¡Happy Hacking!!