En el artículo anterior aprendimos a identificar procesos, vigilar el consumo de recursos y comprobar si un servicio está funcionando. Eso nos permite detectar cuándo algo va mal, pero todavía nos falta una pieza fundamental: entender por qué.
Cuando una aplicación no arranca, un servicio se cae, el sistema tarda demasiado en responder o un usuario no puede autenticarse, Linux suele dejar pistas muy valiosas. Esas pistas viven en los logs, registros que recogen eventos, advertencias, errores y mensajes del sistema a lo largo del tiempo.
La buena noticia es que no necesitas conocer decenas de herramientas ni memorizar todas las rutas del sistema para empezar a aprovecharlos. Si entiendes cómo consultar el journal, qué archivos importantes suelen vivir en /var/log y cómo seguir mensajes en tiempo real, ya tienes una base muy sólida para diagnosticar una gran cantidad de problemas cotidianos.
Qué son los logs y por qué son tan importantes
Un log es, en esencia, un registro cronológico de eventos. Cada vez que el sistema, un servicio o una aplicación quiere dejar constancia de algo relevante, lo escribe ahí: un arranque correcto, una advertencia, un error, un intento de acceso o un fallo de hardware.
La parte importante no es la definición, sino su valor práctico. Los logs convierten un “no funciona” en una secuencia concreta de hechos. Gracias a ellos puedes responder preguntas como estas:
- ¿Qué servicio falló exactamente?
- ¿Cuándo empezó el problema?
- ¿Fue un error de permisos, de configuración o de red?
- ¿El kernel detectó algún problema con el disco, la memoria o un driver?
- ¿Hubo intentos fallidos de autenticación?
Sin logs, solucionar incidencias se parece demasiado a adivinar. Con logs, empiezas a reconstruir el contexto real del sistema.
También conviene asumir algo desde el principio: no todos los logs son iguales. Algunos hablan del sistema en general, otros del kernel, otros de autenticación y otros pertenecen a servicios concretos como Nginx, PostgreSQL o Docker. No necesitas dominarlos todos a la vez, pero sí tener un mapa mental claro de por dónde empezar.
El mapa mental básico del logging en Linux
Uno de los motivos por los que el logging puede confundir al principio es que no existe una única pieza universal e idéntica en todas las distribuciones. La buena noticia es que tampoco hace falta memorizar toda la arqueología del ecosistema.
Piensa en ello así:
- En la mayoría de distribuciones modernas,
systemd-journaldrecoge eventos del sistema y de los servicios gestionados porsystemd. - En muchos equipos también existe
rsyslogo un componente similar que escribe parte de esos eventos en archivos dentro de/var/log. - Algunas aplicaciones escriben sus propios logs directamente en ficheros específicos.
- El kernel genera mensajes propios, que puedes consultar con
dmesgy que a menudo también acaban reflejados en el journal.
Ese es el modelo que importa. No hace falta aprender una lista cerrada de rutas porque cambia según la distribución, la versión y los servicios instalados.
Lo que sí conviene tener claro es esto:
Los procesos y servicios te dicen qué está mal; los logs te ayudan a entender por qué.
Con esa idea, el resto empieza a encajar mucho mejor.
Dónde mirar primero: los logs más importantes
Cuando aún no sabes dónde está el problema, tener demasiadas opciones puede paralizar. Por eso merece la pena reducir el terreno de juego a unas pocas fuentes que cubren la mayoría de incidencias cotidianas.
journald y journalctl
En sistemas modernos con systemd, journalctl suele ser la herramienta principal. Es especialmente útil para:
- ver eventos recientes del sistema;
- inspeccionar servicios gestionados por
systemd; - revisar mensajes del arranque actual;
- filtrar por severidad, unidad o rango temporal.
Si un servicio falla y está bajo systemd, este suele ser el primer sitio donde mirar.
/var/log/syslog o /var/log/messages
Según la distribución, puede existir /var/log/syslog (habitual en Debian y Ubuntu), /var/log/messages (habitual en Red Hat, Fedora o AlmaLinux) o ambos. Son logs generales del sistema y sirven como panorámica amplia cuando quieres ver actividad global sin centrarte todavía en un único componente.
No te obsesiones con el nombre exacto. Lo importante es entender que suele haber algún fichero de “actividad general” mantenido por el sistema de logging clásico.
/var/log/auth.log o /var/log/secure
Aquí suelen aparecer eventos relacionados con autenticación:
- inicios de sesión;
- uso de
sudo; - accesos por SSH;
- intentos fallidos de login.
Si el problema tiene que ver con permisos, acceso remoto o credenciales, este es un sitio muy valioso. En distribuciones Debian/Ubuntu se llama auth.log; en Red Hat y derivados, secure.
dmesg y los mensajes del kernel
Los mensajes del kernel son especialmente útiles cuando sospechas de:
- hardware (discos, memoria, red);
- drivers;
- problemas durante el arranque.
dmesg te da acceso rápido a esa capa del sistema. Además, en muchos entornos parte de esos mensajes también aparecen en el journal.
Logs específicos de servicios
Muchos servicios mantienen sus propios registros. Algunos ejemplos típicos:
- Nginx:
/var/log/nginx/ - Apache:
/var/log/apache2/ - PostgreSQL: varía según distribución y configuración
- Docker: combinado con
journalctlo logs propios de contenedores
Aquí la idea importante es no buscar a ciegas. Si el servicio está gestionado por systemd, empieza por journalctl -u nombre. Si además tiene un directorio de logs propio, úsalo como segunda capa de detalle.
Un resumen mental rápido puede ahorrarte mucho tiempo:
- ¿Falla un servicio? →
journalctl -u nombre - ¿Falla el arranque o hay problemas de hardware? →
dmesgojournalctl -k - ¿Problemas de acceso o autenticación? →
auth.logosecure - ¿Necesitas visión general del sistema? →
journalctlosyslog/messages
Cómo ver logs sin volverte loco
Uno de los errores más comunes es abrir un log enorme y esperar que la respuesta aparezca sola. Casi nunca funciona así. La clave está en filtrar.
Empezar por journalctl
Sin opciones, journalctl muestra una enorme cantidad de mensajes históricos:
journalctl
Puede servir para una visión global, pero rara vez es la mejor forma de empezar. Normalmente tiene más sentido acotar desde el principio.
Por arranque:
journalctl -b
Muestra los mensajes del arranque actual. Muy útil si el problema apareció después de reiniciar.
Por servicio o unidad:
journalctl -u nginx
journalctl -u ssh
Filtra por unidad de systemd. Si sabes qué servicio está fallando, esta opción reduce muchísimo el ruido. Es probablemente la combinación que más usarás.
En tiempo real:
journalctl -f
Sigue el log en tiempo real, parecido a un tail -f. Muy útil cuando vas a reproducir un problema y quieres ver qué aparece justo en ese momento.
Por severidad:
journalctl -p err..alert
Filtra por nivel de prioridad, mostrando errores y situaciones más críticas. Reduce enormemente el volumen de salida en sistemas con mucha actividad.
Por tiempo:
journalctl --since "1 hour ago"
journalctl --since "2026-05-31 10:00:00" --until "2026-05-31 11:00:00"
Limita por tiempo. Especialmente útil cuando sabes aproximadamente cuándo ocurrió la incidencia. Puedes combinar esta opción con -u para acotar todavía más.
La idea no es memorizar todas las opciones, sino acostumbrarte a pensar en filtros: por arranque, por servicio, por severidad o por tiempo.
Navegar archivos de log clásicos
Cuando trabajas con archivos dentro de /var/log, hay tres herramientas sencillas que resuelven casi todo:
tail -f /var/log/syslog
less /var/log/auth.log
grep -i error /var/log/syslog
tail -fsirve para seguimiento en tiempo real del archivo.lesste deja navegar con calma sin volcarlo todo en pantalla de golpe. Puedes buscar dentro con/términoy salir conq.grepayuda a localizar patrones rápidos comoerror,failed,deniedo el nombre de un servicio.
Una combinación muy útil cuando el archivo es grande y buscas algo concreto:
grep -i "failed\|error\|denied" /var/log/auth.log | tail -30
Aquí filtras por varios patrones a la vez y limitas la salida a las últimas 30 coincidencias.
Consultar mensajes del kernel
Para eventos relacionados con el kernel y hardware:
dmesg | less
dmesg --level=err,warn
dmesg -T
--level=err,warn filtra los mensajes más relevantes y evita parte del ruido normal del sistema. -T muestra las marcas de tiempo en formato legible (fecha y hora) en lugar del tiempo transcurrido desde el arranque, lo que facilita correlacionar eventos con otros logs.
Ejemplo práctico: un 403 Forbidden por permisos en Nginx
Nginx está activo y arranca sin problemas, pero al acceder a una URL concreta los usuarios reciben un error 403 Forbidden. El archivo existe en el servidor, pero sus permisos son demasiado restrictivos:
ls -l /usr/share/nginx/html/private.html
-rw------- 1 root root 18 jun 2 10:00 private.html
El primer paso es confirmar el estado del servicio:
systemctl status nginx
Aparece activo y sin errores de arranque, lo que descarta un fallo de configuración global. El problema está en cómo responde a esa petición concreta. El siguiente paso es el log de errores en tiempo real, mientras desde otra terminal se reproduce el fallo:
tail -f /var/log/nginx/error.log
El log muestra la causa de inmediato:
2026/06/01 12:30:10 [error] open() "/usr/share/nginx/html/private.html" failed (13: Permission denied), client: ...
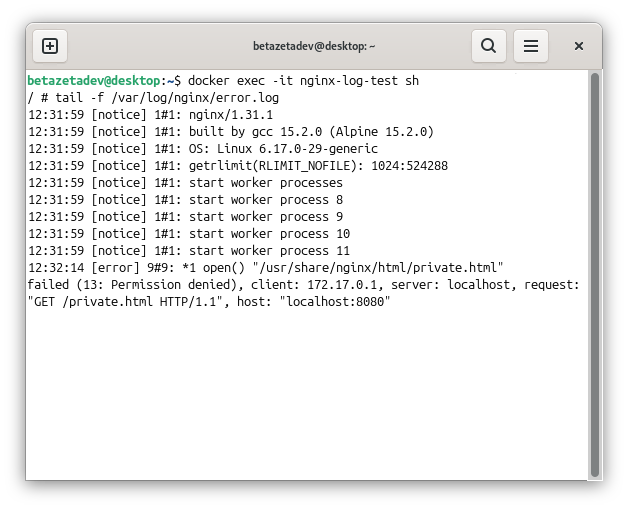
El proceso de Nginx —que en Debian corre habitualmente como www-data— no tiene permisos de lectura sobre el archivo. Los permisos 600 solo permiten acceso al propietario. La corrección es directa:
chmod 644 /usr/share/nginx/html/private.html
Y la petición ya funciona. El flujo completo:
systemctl status nginxdescartó un fallo general del servicio.tail -f /var/log/nginx/error.logcapturó el error exacto en el momento de producirse.- El código
13: Permission deniedseñaló directamente la causa. - Un
chmod 644lo resolvió.
Hay un detalle importante: systemctl status nginx indica que el servicio funciona, y eso podría hacernos pensar que todo va bien. Son los logs los que revelan que el problema ocurre a nivel de petición concreta, no de servicio. Ese matiz marca la diferencia entre buscar un fallo donde no está y encontrarlo rápido donde sí está.
Lo mismo aplica al resto de herramientas del artículo anterior. Si sospechas de puertos, revisa con ss. Si sospechas de recursos, mira memoria o disco. Los logs no sustituyen esas herramientas: las hacen mucho más útiles.
Cómo gestionar el crecimiento de los logs
Los logs son valiosos, pero también crecen. Y si crecen sin control, pueden ocupar cantidades importantes de espacio en disco, especialmente en servidores con mucho tráfico o servicios muy verbosos.
Aquí conviene adoptar una idea clara desde el principio: los logs no se borran a lo loco, se gestionan. Para eso existe logrotate en la mayoría de sistemas Linux.
Qué hace logrotate
logrotate aplica políticas automáticas sobre los archivos de log:
- rota archivos cuando alcanzan cierto tamaño o cierta antigüedad;
- comprime logs antiguos para ahorrar espacio;
- conserva un número limitado de copias históricas;
- elimina el histórico más viejo según las reglas definidas.
Puedes inspeccionar la configuración general y las reglas específicas por servicio así:
ls /etc/logrotate.d/
cat /etc/logrotate.d/nginx
Y antes de lanzar ninguna limpieza, puedes hacer una prueba sin efecto real:
logrotate --debug /etc/logrotate.conf
La opción --debug te muestra qué haría sin ejecutarlo realmente. Es una práctica muy recomendable antes de tocar configuraciones en producción.
Gestionar el tamaño del journal
Si el sistema usa journald, puedes revisar cuánto espacio está ocupando:
journalctl --disk-usage
Y, si hace falta reducirlo, puedes limpiar con criterio:
journalctl --vacuum-time=7d
journalctl --vacuum-size=500M
--vacuum-time=7d elimina entradas con más de siete días de antigüedad. --vacuum-size=500M recorta el almacenamiento total hasta ese límite.
Aquí conviene ser especialmente cuidadoso en entornos de producción. Vaciar registros sin criterio puede dejarte sin la información que necesitas para investigar un problema grave. Antes de limpiar, vale la pena entender por qué están creciendo: mucho tráfico, errores repetidos en bucle, verbosidad excesiva en la configuración de un servicio, o simplemente una política de retención sin ajustar.
La buena práctica no es “borrar porque molesta”, sino “ajustar porque entiendes el coste y el valor de esos datos”.
Buenas prácticas para trabajar con logs
No hace falta complicarlo demasiado. Estos hábitos marcan más diferencia que aprender veinte comandos nuevos:
- No mires solo la última línea: busca contexto antes y después del error. La causa real suele estar unos mensajes más arriba.
- Filtra por tiempo, servicio o nivel para reducir el ruido desde el principio.
- Si investigas algo en vivo, usa
tail -fojournalctl -f. - Si el problema ocurrió durante el arranque, empieza por
journalctl -b. - Si el servicio está bajo
systemd, usajournalctl -uantes de rastrear archivos a ciegas. - No borres logs sin entender primero por qué están creciendo.
- Combina logs con herramientas como
systemctl status,ps,ss,dfofreepara completar el diagnóstico.
Y hay una idea especialmente valiosa para quien viene de otros entornos: un error aislado rara vez cuenta toda la historia. Muchas veces la pista útil no está en la línea exacta del fallo, sino en lo que pasó justo antes. Leer logs no es buscar la línea roja; es reconstruir una secuencia.
Conclusión
Entender logs es uno de los pasos más importantes para dejar de ir a ciegas en Linux. Procesos, servicios y consumo de recursos te ayudan a detectar que algo no va bien; los registros del sistema te ayudan a reconstruir qué ocurrió, cuándo ocurrió y qué componente estuvo implicado.
Y lo mejor es que no necesitas dominar todo el ecosistema de observabilidad para empezar a trabajar bien. Con journalctl, algunos archivos clave dentro de /var/log, dmesg y unas nociones básicas de rotación, ya puedes moverte con mucha más seguridad tanto en un escritorio como en un servidor.
Cuando entiendes lo que ocurre en un sistema, empiezas de verdad a controlarlo.
Happy Hacking!!

