En los artículos anteriores de la serie vimos los fundamentos de Linux, cómo se organiza el sistema y los usuarios, cómo funcionan los permisos y varios comandos útiles para trabajar con más agilidad. Todo eso sirve para entender el sistema “en reposo”: sus archivos, sus usuarios y sus reglas.
Ahora toca mirar Linux en movimiento. Un sistema GNU/Linux siempre está ejecutando tareas, repartiendo recursos y manteniendo servicios activos en segundo plano. Muchas incidencias cotidianas empiezan aquí: una aplicación se congela, una compilación consume toda la CPU, el equipo se queda sin memoria o un servicio deja de responder.
La buena noticia es que no necesitas decenas de herramientas para entender lo que está pasando. Con unos pocos comandos bien elegidos puedes responder a cuatro preguntas clave: qué se está ejecutando, qué está consumiendo recursos, cómo intervenir sin romper nada y cómo comprobar si un servicio del sistema está funcionando.
Qué es un proceso en Linux
Un proceso es, sencillamente, un programa en ejecución. Cuando abres tu navegador, lanzas un editor o ejecutas un script desde la terminal, Linux crea uno o varios procesos para encargarse de ese trabajo.
Cada proceso tiene un identificador único llamado PID (Process ID). Ese número es importante porque muchas herramientas se apoyan en él para consultar información o enviar instrucciones a un proceso concreto.
También conviene tener presentes cuatro ideas:
- Un proceso puede crear otros procesos. Por eso se habla de proceso padre e hijo.
- Cada proceso pertenece a un usuario, igual que los archivos tienen propietario.
- Algunos procesos están en foreground, es decir, conectados a tu terminal actual.
- Otros se ejecutan en background, trabajando en segundo plano sin bloquearte la sesión.
No todo proceso es un servicio. Un proceso puede ser algo puntual, como vim o python script.py. Un servicio, en cambio, suele ser un proceso o conjunto de procesos pensados para permanecer activos y ofrecer una función al sistema o a la red, como ssh, nginx o docker.
Cómo ver procesos en ejecución
Cuando quieres saber qué está haciendo el sistema, el punto de partida suele ser ps. Piensa en él como una foto fija del estado actual.
ps
Así verás los procesos asociados a tu terminal. Es útil, pero normalmente querrás una vista más amplia:
ps aux
ps -ef
Ambos comandos muestran prácticamente todos los procesos del sistema. No es necesario memorizar cada columna, pero sí reconocer las más útiles:
USER: el usuario propietario.PID: el identificador del proceso.%CPUy%MEM: consumo aproximado de procesador y memoria.STAT: estado del proceso.COMMANDoCMD: el comando que lo inició.
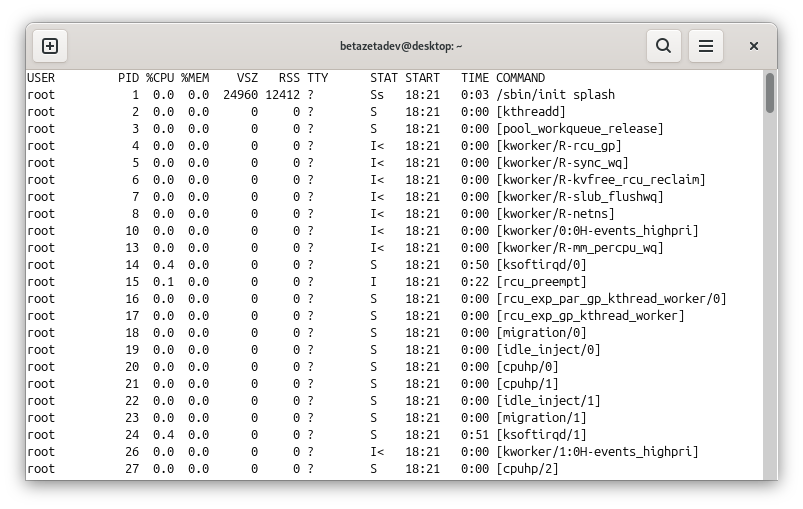
Si buscas algo concreto, lo habitual es filtrar:
ps aux | grep firefox
ps -ef | grep nginx
Esto funciona bien, aunque Linux tiene herramientas más directas para localizar procesos por nombre:
pgrep firefox
pgrep -a python
pidof sshd
pgrep devuelve PIDs que coinciden con un patrón y con -a también muestra el comando completo. pidof resulta cómodo cuando quieres el PID de un binario muy concreto.
Ejemplos cotidianos:
# Buscar si tu navegador sigue abierto
pgrep -a firefox
# Localizar el servidor web Nginx
ps -ef | grep nginx
# Encontrar el PID de un script en ejecución
pgrep -a -f "python backup.py"
La idea importante aquí no es aprender columnas de memoria, sino desarrollar el hábito de localizar rápido qué proceso te interesa y quién lo está ejecutando.
Monitorización en tiempo real con top y htop
ps te da una instantánea. Si el sistema va lento y quieres ver cómo evoluciona la carga en vivo, necesitas monitorización continua.
top
top actualiza la información cada pocos segundos y deja muy claro qué procesos están consumiendo más CPU o memoria. Si tienes htop instalado, la experiencia suele ser más cómoda:
htop
htop no viene siempre preinstalado, pero merece la pena. Es más visual, permite moverte con el teclado y ordenar procesos con más facilidad.
Cuando abras top o htop, fíjate sobre todo en esto:
- CPU: si uno o dos procesos la saturan, probablemente has encontrado el cuello de botella.
- Memoria RAM: si queda muy poca disponible, el sistema empezará a sufrir.
- Swap: si se usa mucho, suele indicar presión de memoria.
- Load average: resume la carga media del sistema en los últimos 1, 5 y 15 minutos.
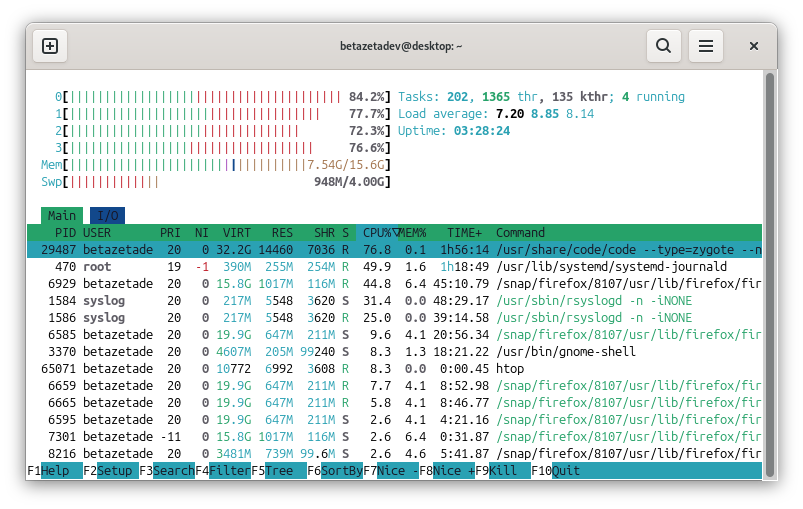
El load average no es exactamente lo mismo que el uso de CPU. Mide cuántos procesos están ejecutándose o esperando turno. Puedes tener una CPU no totalmente saturada y aun así una carga alta si hay muchas tareas compitiendo por recursos o bloqueadas esperando disco.
Dos situaciones típicas:
# Ver en vivo qué proceso dispara la CPU
top
# Usar una vista más cómoda si htop está disponible
htop
- Si un proceso se mantiene arriba con
%CPUmuy alto, ahí está el problema. - Si la RAM libre cae y la swap empieza a crecer, el sistema probablemente está paginando, es decir, moviendo memoria entre la RAM y la swap en disco porque ya no tiene memoria física suficiente.
- Si el load average es alto de forma sostenida, la lentitud puede ser general y no de una sola aplicación.
Cuando un equipo “va raro”, esta suele ser la primera parada útil.
Cómo gestionar procesos sin ir a lo bruto
Una vez localizado el proceso problemático, llega la parte delicada: intervenir sin causar más daño del necesario.
El comando básico es kill, aunque su nombre sea engañoso. No siempre “mata” un proceso de forma inmediata; en realidad envía una señal.
kill 12345
Sin indicar nada más, kill envía SIGTERM, una señal de Linux para pedirle a un proceso que se cierre de forma ordenada. Es la primera opción porque da margen a cerrar archivos, liberar recursos o guardar estado.
También puedes actuar por nombre:
pkill firefox
killall node
Las señales más útiles en el día a día son estas:
SIGTERM: intento de cierre limpio.SIGKILL: finalización forzada e inmediata.SIGSTOP: pausa el proceso.SIGCONT: reanuda un proceso pausado.
Ejemplos prácticos:
# Cerrar una aplicación congelada de forma limpia
kill 12345
# Si no responde, forzar el cierre como último recurso
kill -9 12345
# Detener todos los procesos de un script por nombre
pkill -f "python backup.py"
# Pausar y reanudar temporalmente un proceso
kill -STOP 12345
kill -CONT 12345
kill -9 equivale a SIGKILL y no debería ser tu primera reacción. Si fuerzas el cierre demasiado pronto puedes dejar archivos a medias, sockets abiertos o estados inconsistentes. Primero prueba SIGTERM y solo escala si realmente no responde.
Foreground, background y control de trabajos
Uno de los trucos más útiles en terminal es entender la diferencia entre ejecutar en el frente o dejarlo trabajando en segundo plano.
Si lanzas un comando normal, se queda en foreground y bloquea la terminal hasta terminar:
python script_largo.py
Si sabes desde el principio que quieres seguir usando la terminal, añádelo al fondo con &:
python script_largo.py &
Para ver los trabajos asociados a tu sesión actual:
jobs
Y para moverlos entre primer y segundo plano:
bg %1
fg %1
Un flujo muy habitual es este:
# Lanzar una tarea larga
python script_largo.py
# Suspenderla con Ctrl+Z y mandarla al fondo
bg
# Recuperarla después
fg
Si la tarea debe seguir viva incluso al cerrar la terminal, usa nohup:
nohup python script_largo.py > salida.log 2>&1 &
Esto resulta muy útil para exportaciones, copias de seguridad o scripts que tardarán bastante y no quieres perder al cerrar la sesión SSH.
Prioridad de procesos con nice y renice
No todos los procesos tienen por qué competir en igualdad de condiciones. Linux permite ajustar su prioridad para que una tarea pesada moleste menos al resto del sistema.
Con nice puedes lanzar un proceso con menor prioridad:
nice -n 10 make -j8
Cuanto más alto es el valor de nice, menos prioridad tiene el proceso. Esto viene muy bien para compilaciones, conversiones de vídeo o tareas intensivas que pueden esperar un poco.
Si el proceso ya está en marcha, puedes cambiar su prioridad con renice:
renice 10 -p 12345
Caso práctico:
# Compilación intensiva sin castigar tanto el escritorio
nice -n 10 npm run build
En entornos concretos, un administrador puede querer dar más prioridad a un proceso crítico, pero eso suele requerir permisos elevados y debe hacerse con criterio. En la mayoría de escenarios cotidianos, lo útil es saber bajar prioridad a una tarea pesada para que no arruine tu sesión.
Cómo vigilar memoria, disco y carga del sistema
No todo problema de rendimiento se detecta mirando procesos individuales. A veces necesitas una vista rápida del estado general del sistema.
Memoria
free -h
Aquí verás RAM usada, disponible, caché y swap. La columna más útil hoy suele ser available, porque Linux aprovecha memoria libre como caché y eso no significa necesariamente un problema.
Si la memoria disponible es baja y la swap crece, el sistema puede empezar a responder con mucha lentitud.
Disco
df -h
du -sh ~/Descargas
df -h muestra el espacio total y libre por sistema de archivos. du -sh sirve para saber cuánto ocupa una carpeta concreta.
La diferencia es importante:
df -hresponde “cuánto disco queda”.du -shresponde “cuánto ocupa esta ruta”.
Carga media
uptime
Además de mostrar cuánto tiempo lleva encendido el sistema, uptime enseña el load average. Es una forma rápida de comprobar si la máquina lleva un rato trabajando por encima de lo normal.
Con estas herramientas puedes hacer un diagnóstico inicial bastante sólido:
- Si falta RAM, mira
free -h. - Si sospechas de espacio, empieza por
df -hy luego baja a carpetas condu -sh. - Si notas lentitud general, revisa
uptimey compáralo con lo que ves entop.
Qué es un servicio en GNU/Linux
Un servicio es un proceso, o un conjunto de procesos, que normalmente se ejecuta en segundo plano para ofrecer una función al sistema o a otros equipos de la red.
Por ejemplo:
sshpermite conexiones remotas.nginxsirve contenido web.cronprograma tareas periódicas.dockergestiona contenedores virtuales.
Muchas veces oirás también el término daemon. En la práctica se usa para referirse a esos procesos de fondo que permanecen activos esperando trabajo.
En la mayoría de distribuciones modernas, estos servicios se administran con systemd, y su herramienta principal es systemctl.
Gestión básica de servicios con systemctl
Si sospechas que un servicio no está funcionando, empieza comprobando su estado:
systemctl status ssh
systemctl status nginx
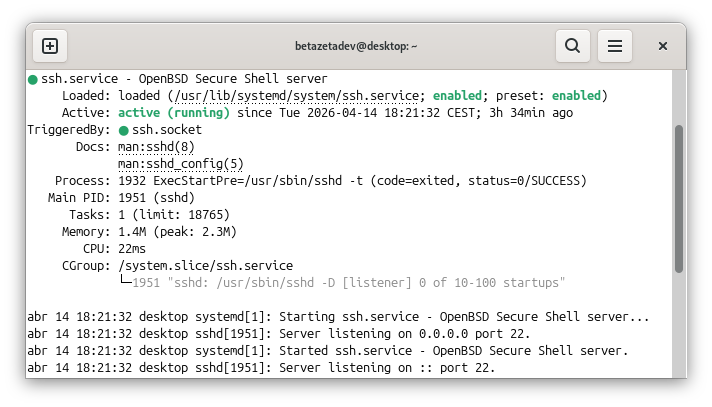
Eso te dará la información necesaria del estado del servicio, desde ahí puedes arrancarlo, detenerlo o reiniciarlo:
sudo systemctl start nginx
sudo systemctl stop nginx
sudo systemctl restart nginx
También puedes decidir si debe arrancar automáticamente con el sistema:
sudo systemctl enable docker
sudo systemctl disable docker
Aquí hay una diferencia muy importante:
systemctl startinicia el servicio ahora mismo.systemctl enablehace que arranque automáticamente en próximos inicios.
No son equivalentes. Puedes tener un servicio arrancado pero no habilitado al inicio, o habilitado para futuros reinicios pero parado en este momento.
Ejemplos cotidianos:
# Comprobar si SSH está activo
systemctl status ssh
# Reiniciar Nginx tras cambiar su configuración
sudo systemctl restart nginx
# Hacer que Docker arranque con el sistema
sudo systemctl enable docker
Detener un proceso y detener un servicio tampoco es exactamente lo mismo. Si matas el proceso principal con kill, quizá el gestor del servicio intente levantarlo otra vez. Si lo que quieres es administrar un servicio del sistema, normalmente debes hacerlo con systemctl.
Un flujo práctico de troubleshooting
Con todos estos comandos puedes seguir un recorrido mental bastante claro.
1. Una aplicación deja de responder
pgrep -a firefox
top
kill PID
kill -9 PID
Primero la localizas, luego compruebas si está consumiendo recursos de forma anómala y después intentas cerrarla limpiamente. Solo si no responde pasas a kill -9.
2. El sistema va lento
top
free -h
uptime
Mira si la CPU está saturada, si falta memoria o si la carga media lleva tiempo disparada. Cuando identifiques el proceso conflictivo, puedes terminarlo o bajar su impacto con renice.
3. Una tarea larga te bloquea la terminal
jobs
bg
fg
nohup comando &
Si ya la lanzaste, puedes suspenderla y mandarla al fondo. Si debe sobrevivir al cierre de sesión, relánzala con nohup.
4. Un servicio no funciona como esperas
systemctl status nginx
sudo systemctl restart nginx
sudo systemctl enable nginx
Comprueba su estado, reinícialo si procede y verifica si está configurado para arrancar automáticamente. Más adelante, en otro artículo, hablaremos específicamente de logs y diagnóstico profundo con journald y otros registros del sistema, que es donde continuarías si el problema persiste.
Buenas prácticas para no complicarte la vida
- No empieces por
kill -9; prueba antes un cierre limpio conSIGTERM. - Revisa qué proceso vas a detener antes de hacerlo, especialmente si trabaja como
rooto pertenece al sistema. - No ejecutes todo como administrador, por lo general no hace falta, sólo cuando sea estrictamente necesario.
- Distingue entre una aplicación de usuario y un servicio gestionado por
systemd. - No confundas alta carga de CPU con falta de memoria: son problemas distintos y se diagnostican de forma distinta.
- Antes de reiniciar un servicio “a ciegas”, consulta su estado con
systemctl status.
Conclusión
Entender procesos, recursos y servicios es uno de los saltos más importantes para dejar de usar Linux por encima y empezar a controlarlo de verdad. Con unas pocas herramientas muy bien elegidas ya puedes inspeccionar qué se está ejecutando, medir su impacto, intervenir con seguridad y mantener servicios básicos bajo control.
Además, este conocimiento es útil tanto en escritorio como en servidor. Cambia el contexto, pero las preguntas son las mismas: qué está pasando, qué recurso falta y cuál es la forma correcta de actuar.
En el siguiente artículo de la serie, el paso natural será profundizar en los logs y el diagnóstico del sistema. Ahí veremos cómo entender mejor por qué un proceso o un servicio ha fallado, en lugar de limitarnos a detectar que algo no va bien.
Happy Hacking!!


