
Administración de Hasura a fondo
Hemos visto las funcionalidades básicas para gestionar nuestros datos que GraphQL nos ofrece. Las …
leer másHemos visto las funcionalidades básicas para gestionar nuestros datos que GraphQL nos ofrece.
Operaciones como Query, Mutation y Subscription de GraphQL nos permiten obtener, crear, actualizar y eliminar datos con una sintaxis muy simple y fácil de aprender.
Ahora vamos a ver las diferentes opciones que Hasura nos proporciona por defecto para gestionar la base de datos, ejecutar tareas del lado del servidor o conectarse a servicios externos.
Para este ejemplo vamos a descargar una base de datos ya llena de datos de muestra, específicamente la que contiene información de un negocio de alquiler de películas llamado Pagila.
Simplemente necesitamos importar el esquema y los datos de muestra con psql. Luego, podemos crear la conexión a la base de datos virtualizada desde el panel de Hasura como vimos en el primer capítulo de la serie.
En el archivo docker-compose tenemos que agregar la cláusula ports a la sección postgres para poder conectarnos desde nuestra máquina anfitriona:
version: '3.6'
services:
postgres:
image: postgres:12
ports:
- "5432:5432"
volumes:
...
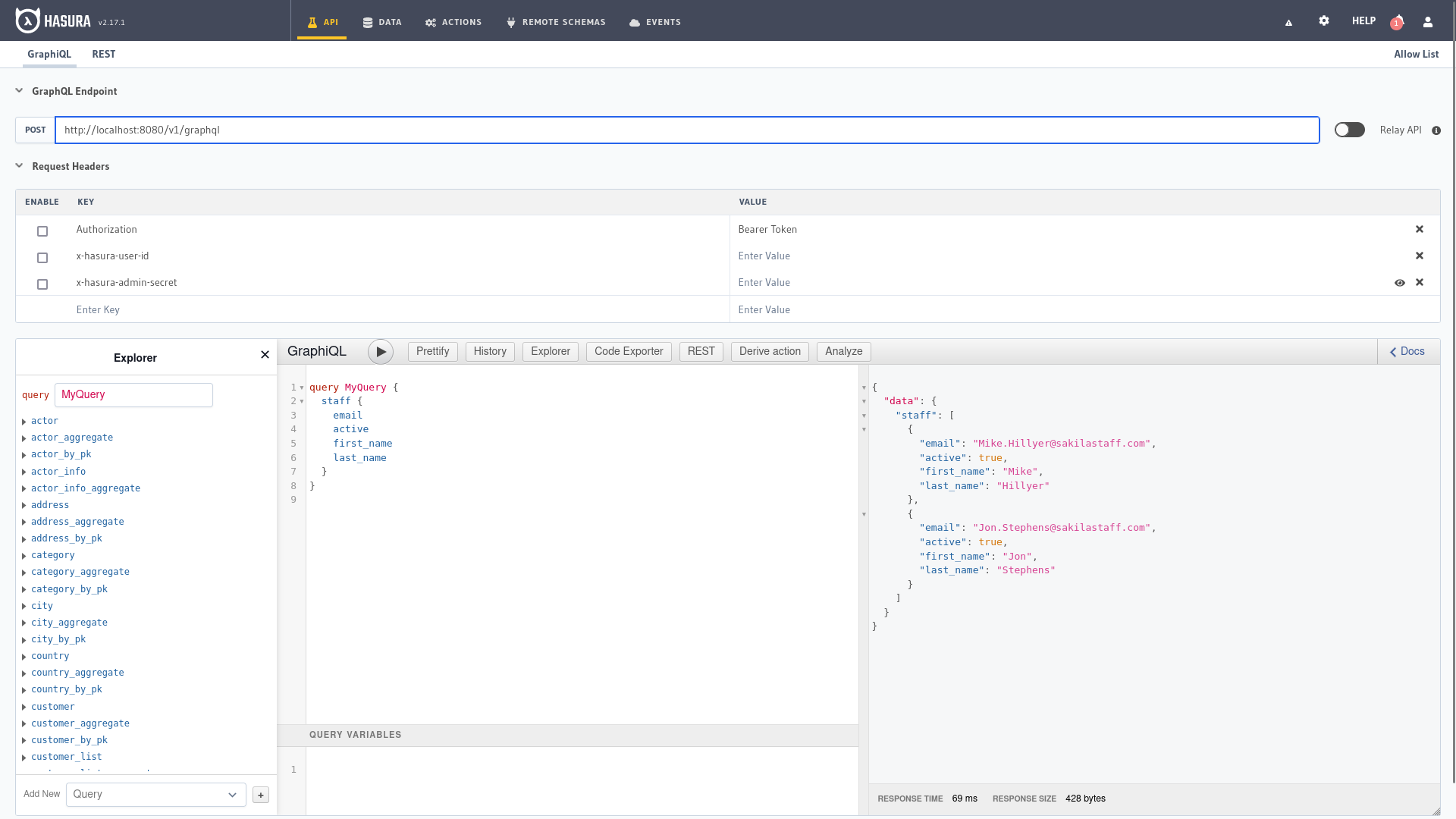
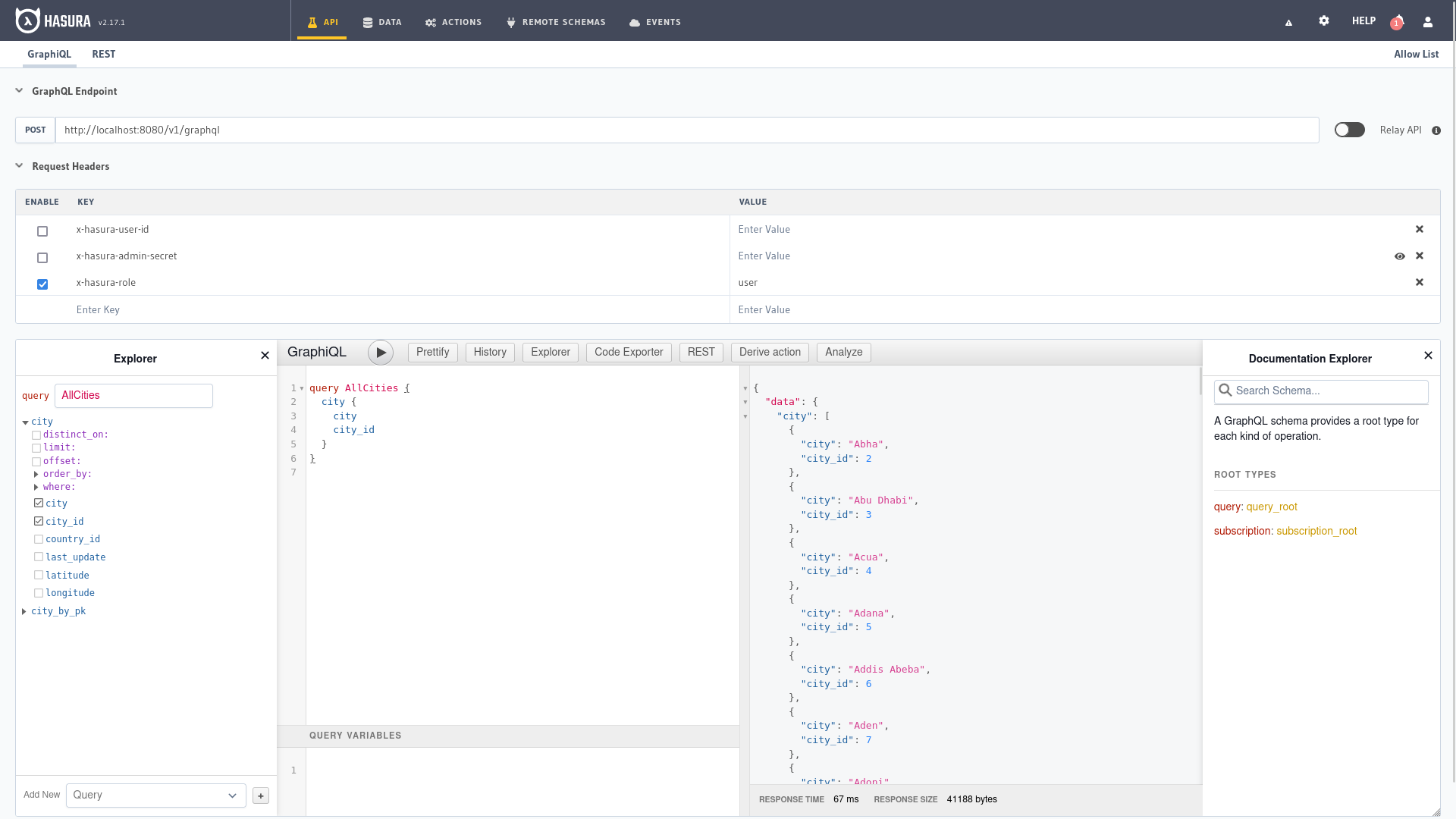
Esta es la primera pantalla que encontramos cuando ingresamos al panel de administración de Hasura, donde tenemos varias partes bien diferenciadas.
En la parte superior está la URL de nuestro endpoint y los parámetros incluidos en el encabezado de la solicitud de la API.
En el lado izquierdo, el explorador para navegar a través de las diferentes entidades, GraphiQL para hacer consultas en el centro y
la documentación donde consultar los diferentes parámetros y opciones disponibles a la derecha. En la parte inferior escribiríamos los
valores de las variables en formato JSON si las solicitudes utilizan variables en GraphiQL.
En el capítulo anterior ya vimos múltiples ejemplos que podemos copiar y adaptar para ejecutar aquí mismo o podemos usar el explorador para construir nuestra consulta con los diferentes filtros, opciones de selección y ordenación desde el explorador.
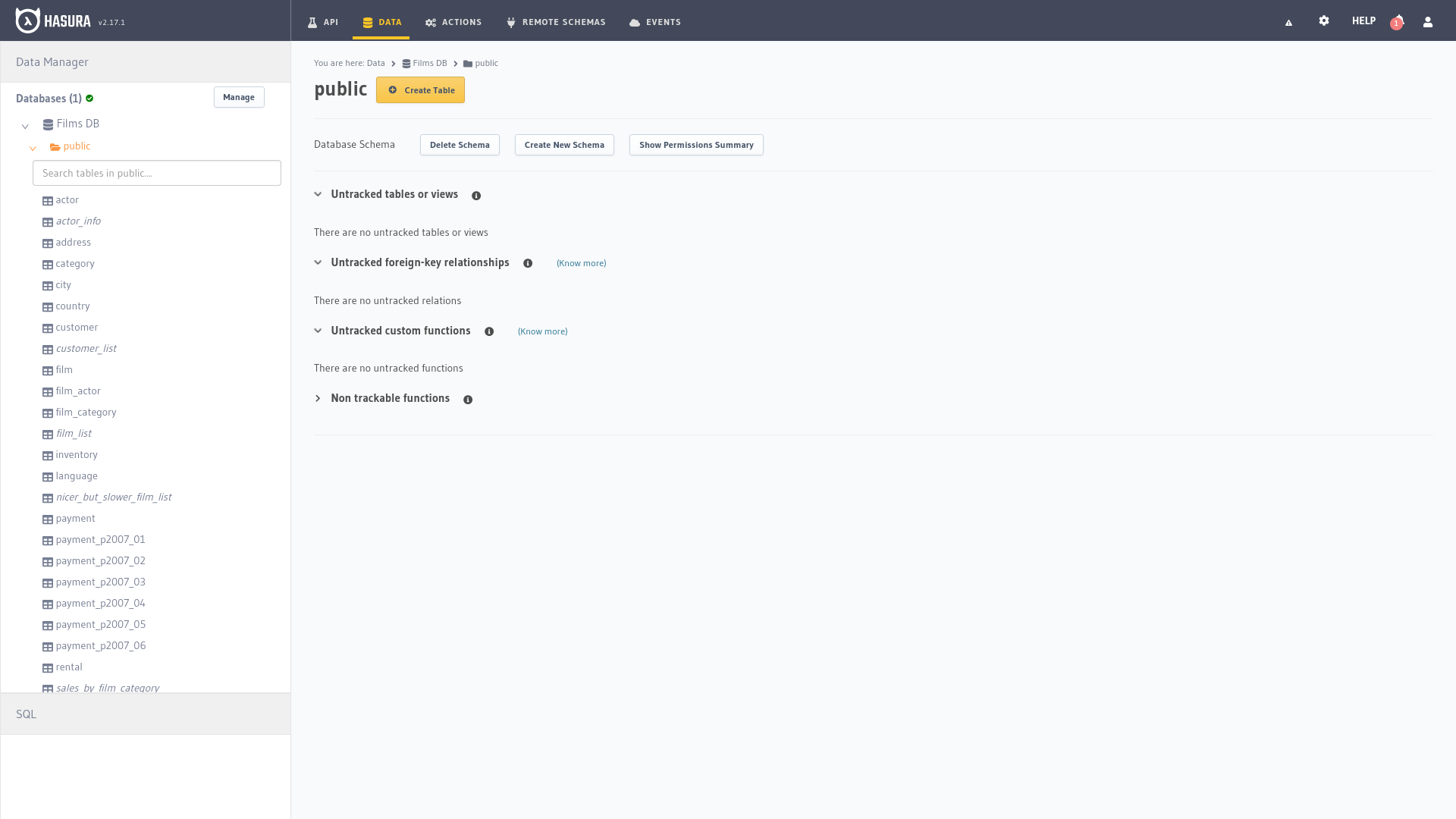
Tan pronto como abrimos la segunda pestaña encontramos un gestor de datos a la izquierda y a la derecha las tablas que están siendo rastreadas y las que no lo están. En la parte inferior izquierda hay un botón que abrirá una ventana para ejecutar consultas SQL manualmente.
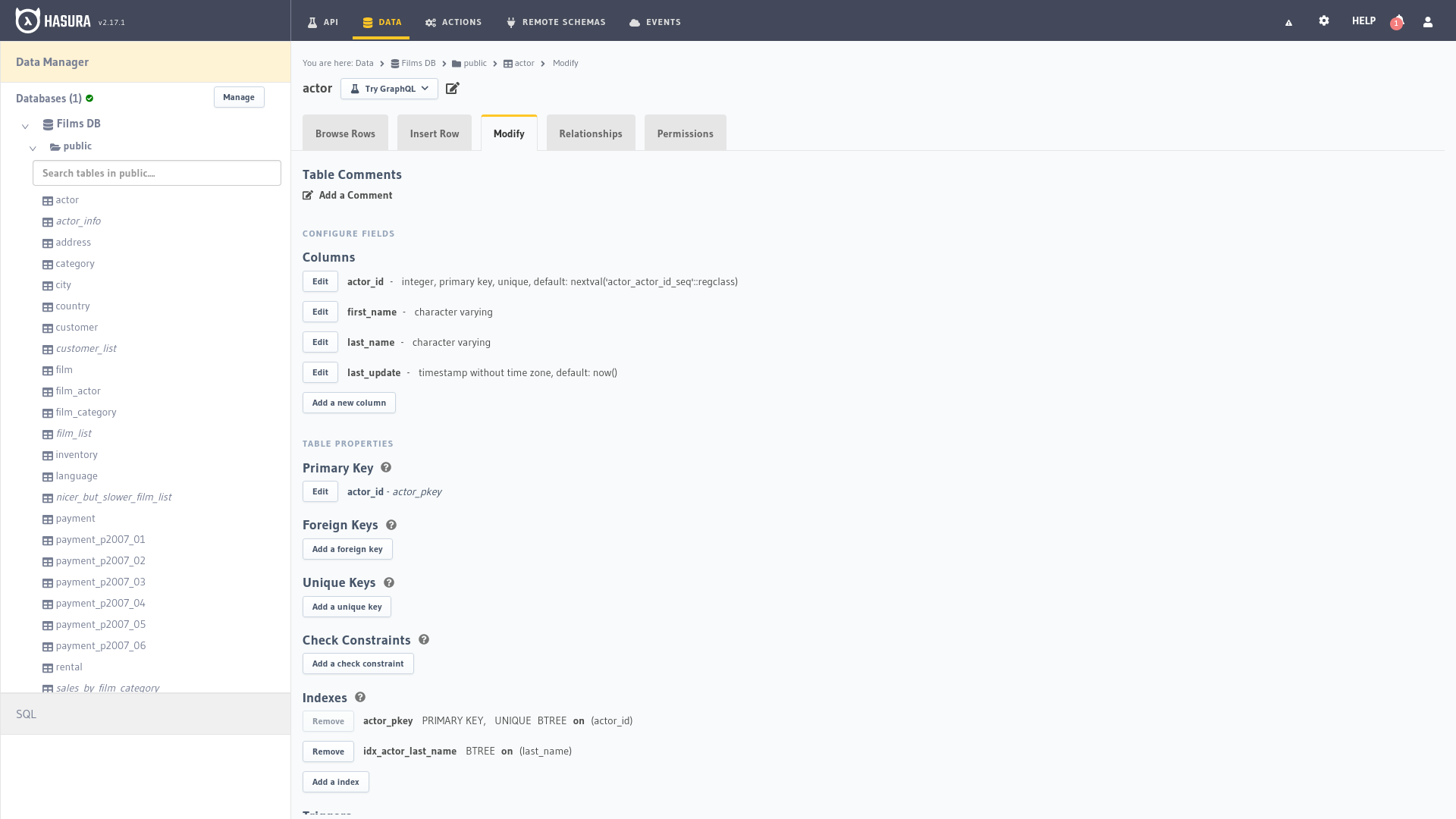
Seleccionando cualquiera de las entidades en el lado izquierdo, el gestor nos mostrará los registros de la tabla, así como nos permitirá agregar nuevas filas o modificar las existentes, las relaciones entre las entidades y los permisos para acceder a los datos a través de la API.
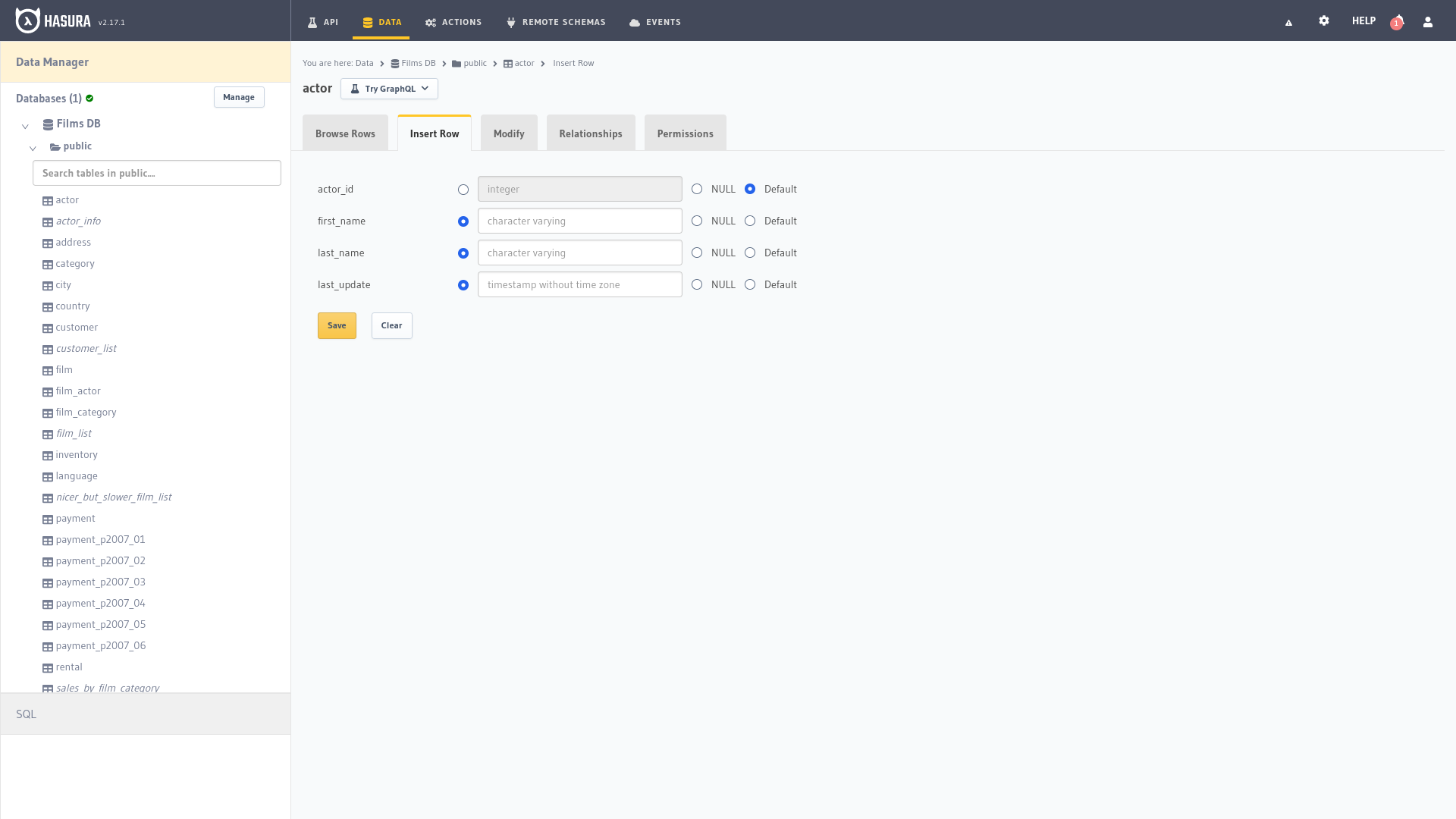
En este punto simplemente tenemos que llenar los campos para insertar un nuevo registro en la tabla seleccionada.
La pestaña Modificar nos permite cambiar los parámetros de las diferentes columnas y agregar nuevas, triggers, restricciones,
índices, etc. También nos permite configurar la tabla como un tipo enum para datos fijos o crear un campo calculado.
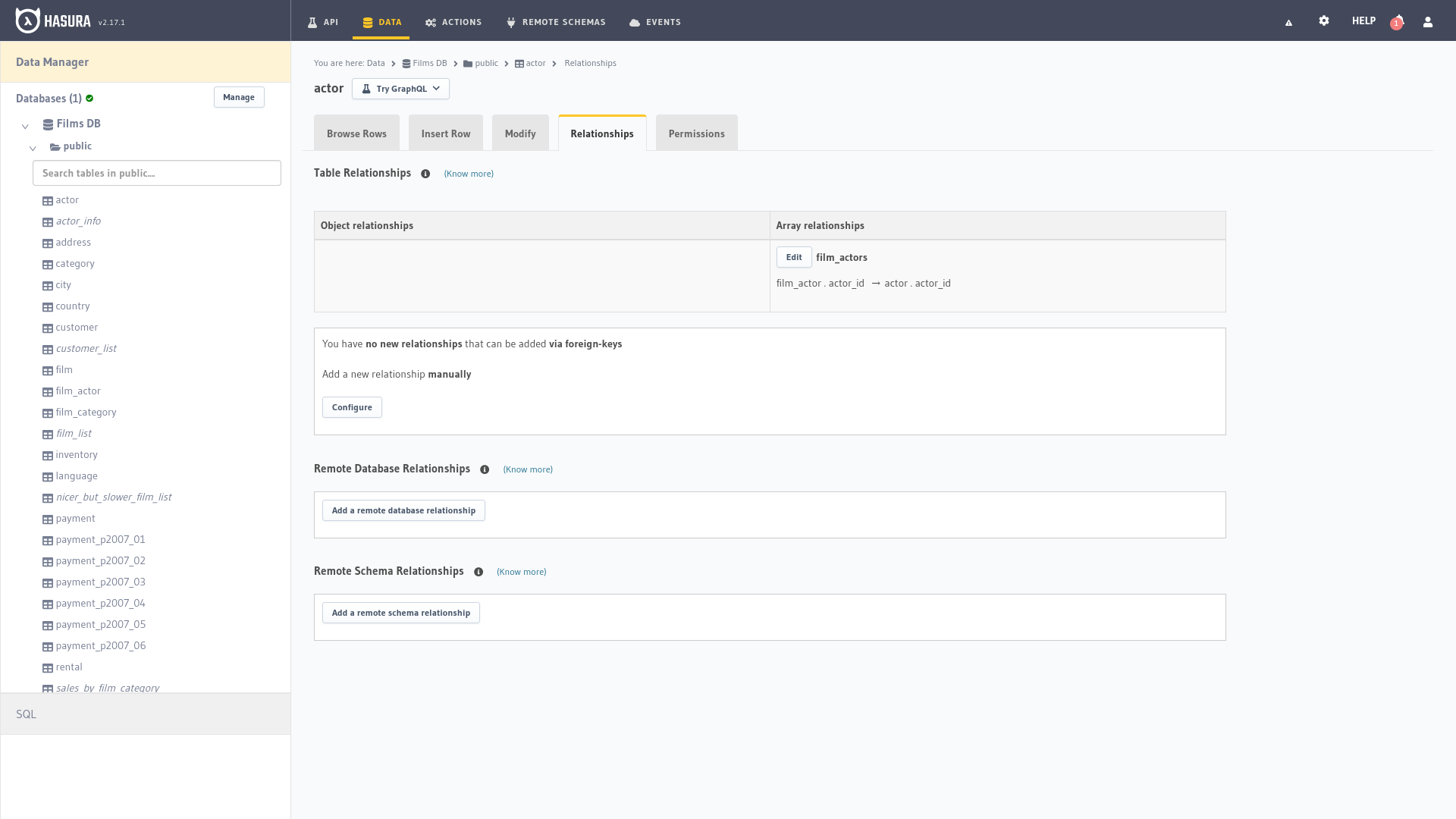
Nos permite gestionar las relaciones entre las diferentes entidades de nuestra base de datos de forma independiente.
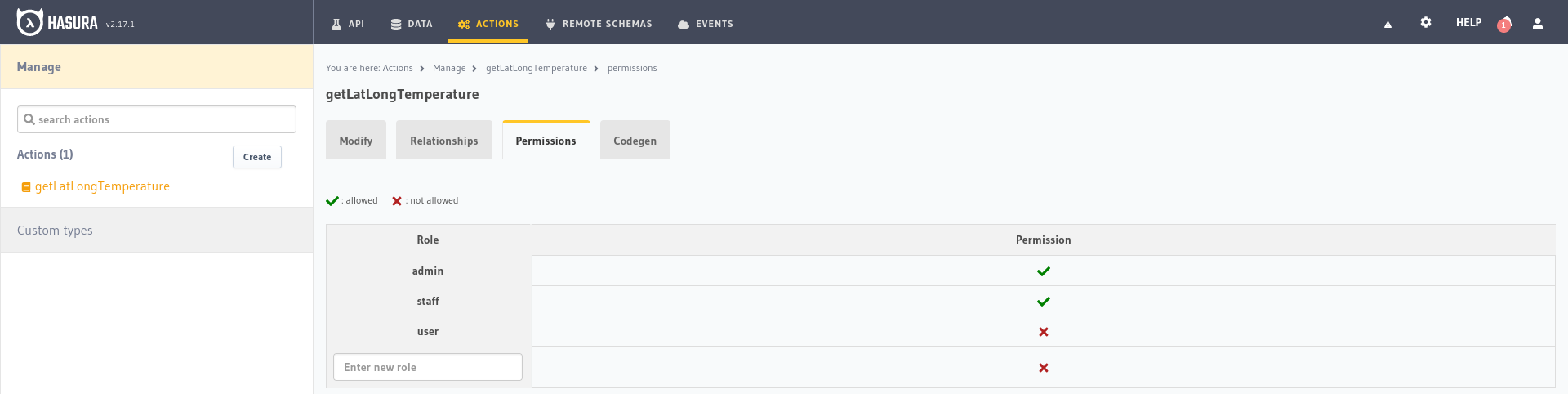
La sección de roles y permisos se usa para establecer los controles de acceso a los datos a través de consultas de la API, quién puede insertar, acceder, modificar o eliminar qué datos y cómo, las variables que pueden consultar, etc. Esto usando un sistema de roles y permisos lo suficientemente flexible como para cubrir la mayoría de los casos de uso básicos.
Podemos diseñar un rol de usuario simple con acceso limitado a consultas y modificaciones, un rol de moderador que puede modificar algunas tablas que el usuario no puede, o un rol de usuario para el personal que tiene acceso a ciertas tablas que el usuario básico y el moderador no tienen, etc.
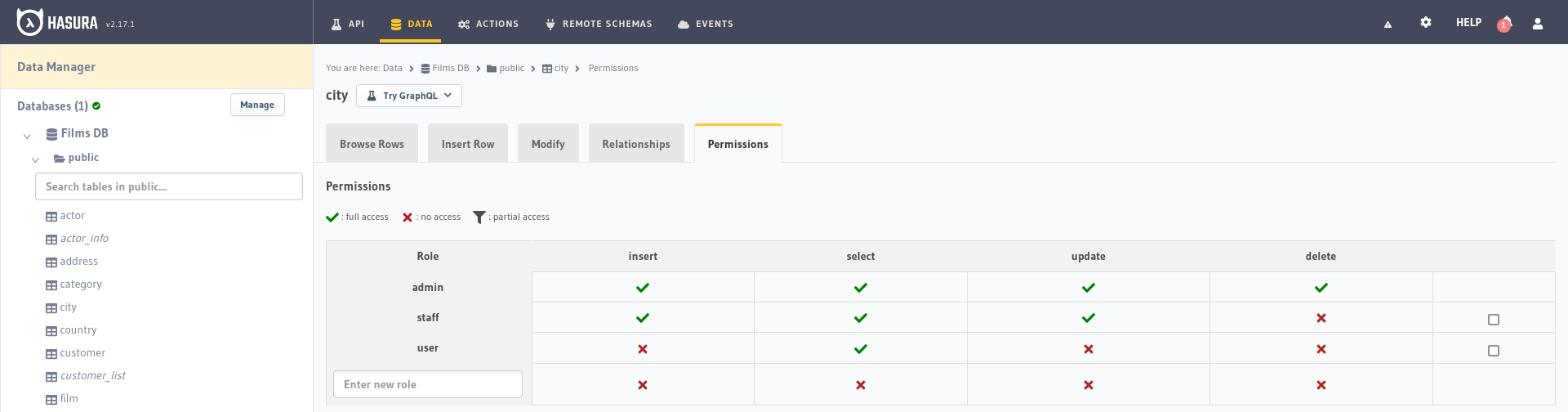
Si seleccionamos la tabla city en el lado izquierdo podremos crear los roles de usuario, en el campo de texto que dice Enter new role,
escribimos user y hacemos clic en la cruz roja en la columna Select para abrir el formulario de permisos:
Permisos de selección de filas: Nos permite establecer algún filtro usando las variables del encabezado en la solicitud u otros
campos en la base de datos. Lo dejamos sin restricciones activando Without any checks.Permisos de selección de columnas: Indica qué parámetros de la entidad estarán influenciados por esta regla. Presionamos el botón Toggle all
para habilitar todos los campos haciéndolos accesibles para este rol.Permisos de consulta de agregación: Nos permite indicar si este rol de usuario tiene permisos para realizar consultas de agregación,
como totales o promedios, máximos o mínimos. Podemos dejarlo por defecto.Permisos del campo raíz: Para gestionar los permisos del elemento raíz, si está desactivado, todos están permitidos por defecto.Creamos el nuevo rol de usuario user con permisos de selección en la tabla city sin ningún tipo de restricción en los
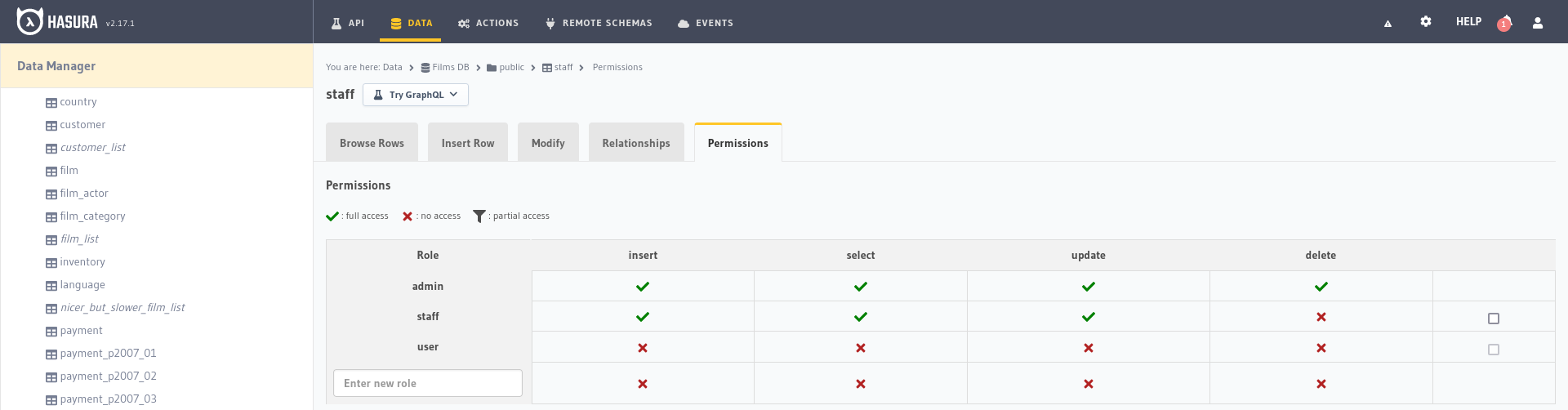
parámetros a seleccionar. Ahora podemos repetir el proceso para crear el rol staff y darle los permisos para insertar,
seleccionar y modificar.
Para verificar que los permisos se están comprobando correctamente, vamos a la pestaña API y añadimos al encabezado de la solicitud la clave
x-hasura-role con el valor user. Veremos que solo podemos recolectar los datos de city, mientras que si lo cambiamos
a staff, también podemos acceder a los datos del rol de staff.
Una acción es un evento que se ejecuta en el servidor después de una llamada a la API, nos permite ejecutar ciertas acciones que no corresponderían a las habituales, fuera de la lógica de negocio.
Imaginemos que en una de nuestras aplicaciones queremos mostrar el clima actual en una ciudad específica, podríamos llamar directamente
a la API de Clima Gratis de OpenMeteo desde el cliente o podríamos crear una acción en nuestro Hasura
que actuaría como intermediario y se encargaría de solicitar a OpenMeteo la temperatura cuando lo llamemos desde el cliente.
Este tipo de funcionalidad está diseñada para gestionar nuestros datos que pueden requerir algún tipo de operación especial. Tal como lo estamos haciendo ahora, tiene la desventaja de que hacemos dos solicitudes en lugar de la única que necesitaríamos si hiciéramos la solicitud directamente. Aunque también tiene la ventaja de que, si ocurre un error o se requiere un cambio en la solicitud, no sería necesario actualizar las aplicaciones del cliente.
Es responsabilidad del equipo de desarrollo estimar las ventajas y desventajas para determinar qué método es mejor para el caso de uso del proyecto, esto es solo un ejemplo.
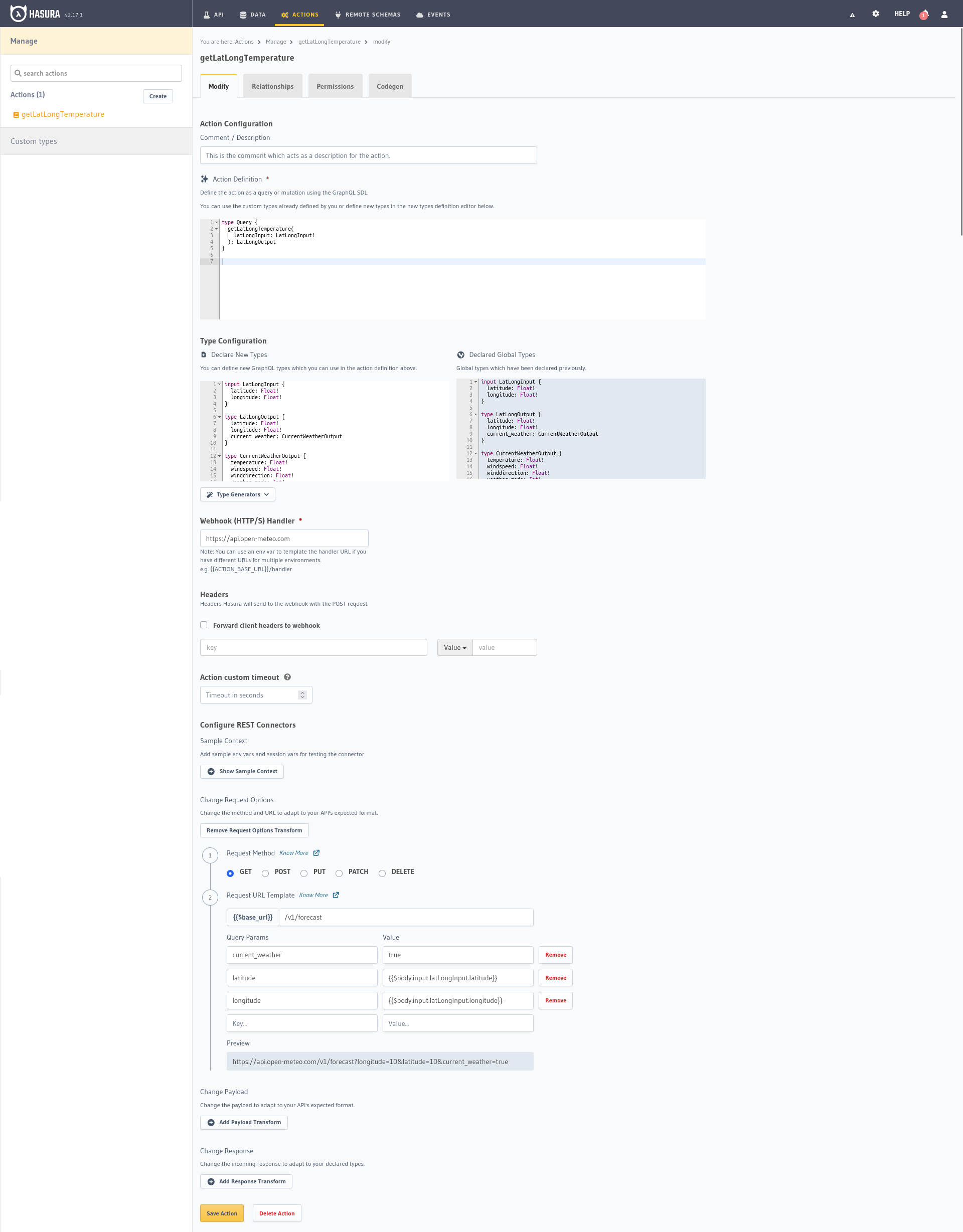
Para comenzar, definiremos el formato de la acción, la solicitud que se realizará, en el cuadro Action Definition.
type Query {
getLatLongTemperature(
latLongInput: LatLongInput!
): LatLongOutput
}
En el siguiente cuadro Type Configuration creamos los tipos de datos, podríamos asociarlos con el concepto de Clase de la
programación orientada a objetos, definen la estructura de los datos que se recibirán (Input) y se responderán (Output)
durante la ejecución de la acción.
input LatLongInput {
latitude: Float!
longitude: Float!
}
type LatLongOutput {
latitude: Float!
longitude: Float!
current_weather: CurrentWeatherOutput
}
type CurrentWeatherOutput {
temperature: Float!
windspeed: Float!
winddirection: Float!
weather_mode: Int!
time: String
}
Tanto LatLongOutput como CurrentWeatherOutput (que es un subconjunto del primero) corresponden a la respuesta que
recibiremos de la API de OpenMeteo, que es similar a la que se muestra a continuación:
{
"latitude": 51.5,
"longitude": -0.120000124,
"generationtime_ms": 0.2110004425048828,
"utc_offset_seconds": 0,
"timezone": "GMT",
"timezone_abbreviation": "GMT",
"elevation": 27.0,
"current_weather": {
"temperature": 5.0,
"windspeed": 5.9,
"winddirection": 259.0,
"weathercode": 0,
"time": "2023-01-30T20:00"
}
}
Aquí recogemos las variables que podemos usar en algún momento en cualquiera de nuestros clientes, luego en cada solicitud podemos especificar exactamente qué datos queremos en cada caso.
En el Webhook Handler tenemos que agregar la URL del endpoint al que se enviará la solicitud, la de OpenMeteo: https://api.open-meteo.com
Vamos a abrir la opción Add request options transform para agregar los parámetros que queremos enviar a la API de OpenMeteo, básicamente la bandera current_weather, latitude y longitude.
Método de petición: GET{{$base_url}}: /v1/forecastcurrent_weather: truelatitude: {{$body.input.latLongInput.latitude}}longitude: {{$body.input.latLongInput.longitude}}Usando {{$body.input.latLongInput.latitude}} accedemos al valor de latitud en el cuerpo de la solicitud de entrada, una vez que terminemos debería mostrarnos una dirección temporal en la Vista previa a continuación: {{$body.input.latLongInput.latitude}}.
https://api.open-meteo.com/v1/forecast?longitude=10&latitude=10¤t_weather=true
Enlace que podemos consultar directamente en el navegador para verificar que funciona y devuelve los datos que esperamos.
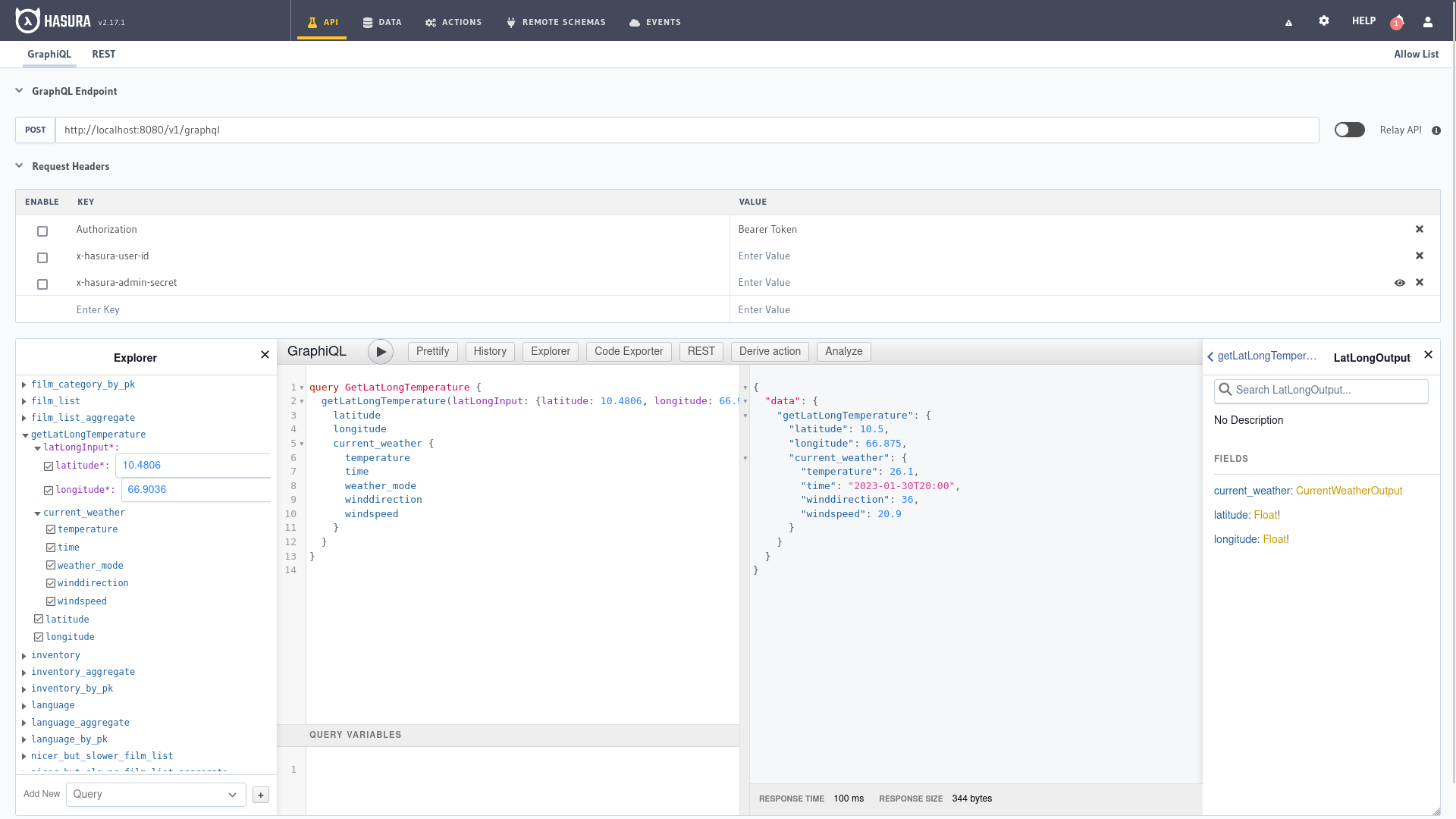
Ahora podemos probar la acción desde el panel de administración de Hasura, en la pestaña API ingresamos la siguiente consulta:
query GetLatLongTemperature {
getLatLongTemperature(latLongInput: {latitude: 10.4806, longitude: 66.9036}) {
latitude
longitude
current_weather {
temperature
time
weather_mode
winddirection
windspeed
}
}
}
También podríamos limitar el acceso a esta función usando permisos, tal como lo hacemos con las tablas de la base de datos. Asumiendo que la temperatura
es una funcionalidad disponible solo para los usuarios con rol de staff, la restringiríamos para que solo su rol pueda acceder desde la pestaña Permissions
dentro de las opciones de la acción.
Con los esquemas remotos podemos conectar esquemas GraphQL de otras fuentes en caso de que tengamos alguna API adicional de GraphQL y queramos unificarlas.
A diferencia de las acciones, los eventos se ejecutan automáticamente cuando se realiza una operación en la base de datos, ya sea desde la API o desde
cualquier otra fuente, el equivalente a los triggers en PostgreSQL.
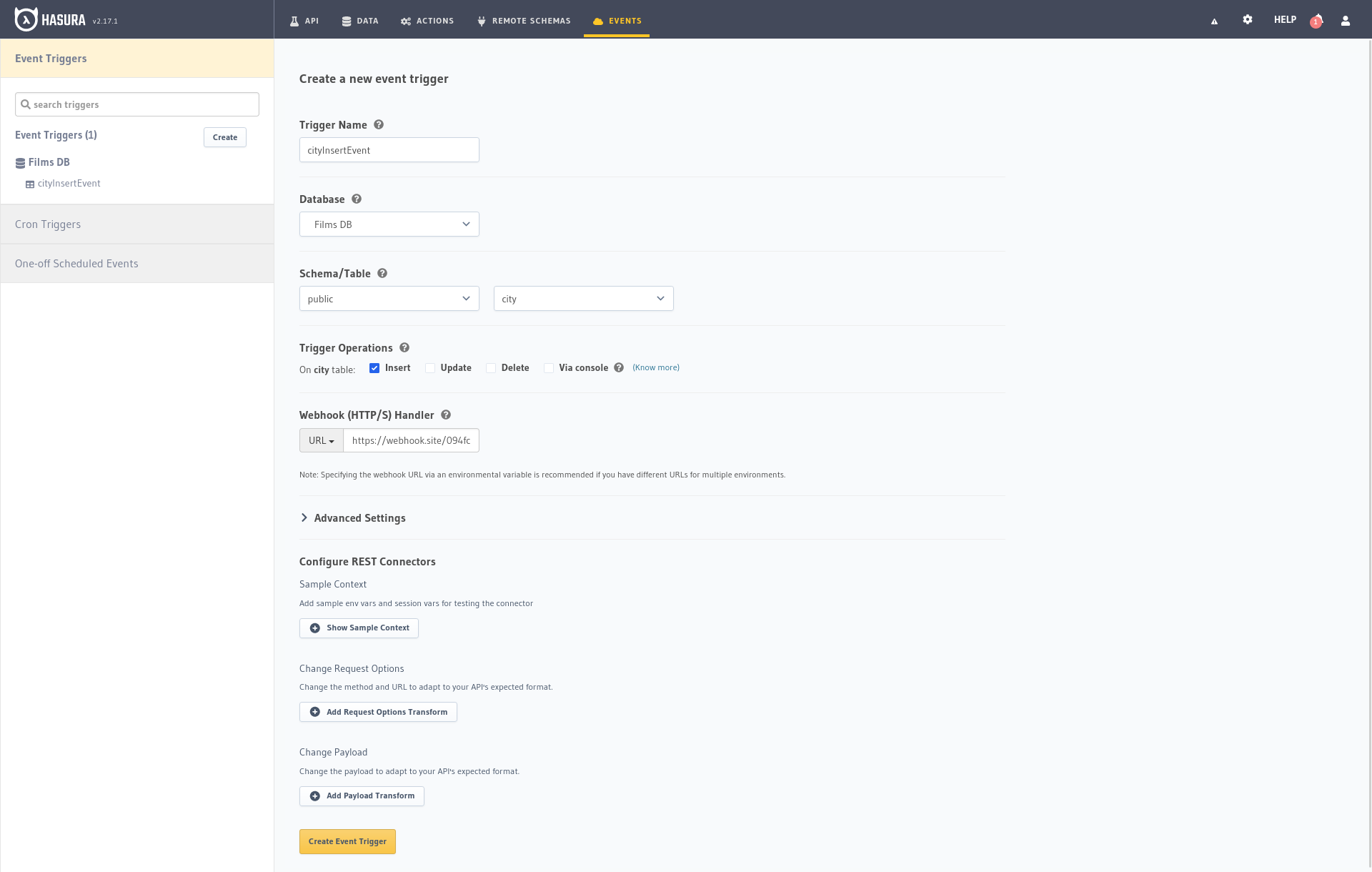
Se utilizan principalmente para llamar funciones serverless o webhooks que se ejecutarán cuando ocurra un evento. Para probarlo, vamos a entrar en Webhook.site y copiar la URL que nos proporciona para agregarla
en la configuración de nuestro evento como Webhook URL.
Llenamos el formulario de la siguiente manera:
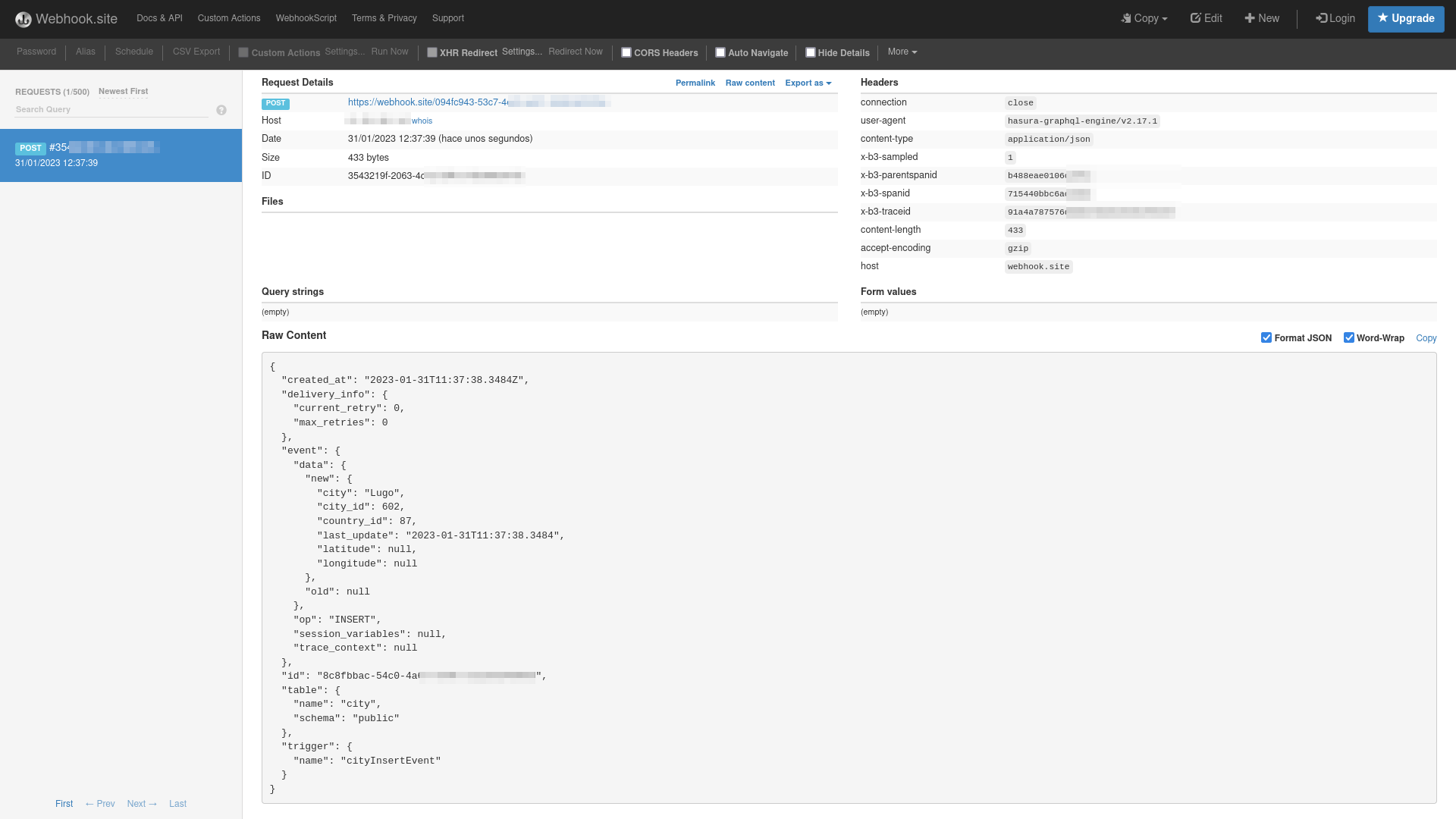
Event Name: Le he dado “cityInsertEvent” pero puedes darle el nombre que quieras.Database: “Films DB”, el nombre que le dimos cuando la creamos.Schema: “public”.Table: “city” o la tabla en la que queremos que se ejecute el evento.Trigger Operation: Selecciona Insert para notificarnos cada vez que se inserte una nueva ciudad.Webhook URL: La URL proporcionada por Webhook.siteAhora podemos insertar desde cualquier fuente (el propio panel de Hasura) una nueva ciudad para verificar que nuestro evento se ejecuta y nos notifica automáticamente en el servidor que hemos indicado con la URL. En el panel de Webhook.site veremos toda la información de la solicitud recibida con los datos de la solicitud recibida con los datos que se insertaron si todo ha ido bien.
Al seleccionar el evento que acabamos de crear en el panel de administración de Hasura, podemos ver las solicitudes procesadas, pendientes y los registros que mantienen un historial de las llamadas a funciones.
Los Cron triggers nos permiten ejecutar eventos periódicamente, por ejemplo, para realizar una limpieza de la base de datos y los One-off scheduled events
nos permiten ejecutar eventos programados en un momento específico.
Hemos revisado casi todas las funciones disponibles en Hasura y hemos jugado con sus acciones, eventos y roles. No son tan fundamentales como la gestión de datos por defecto, pero proporcionan un valor añadido que puede ser muy útil en muchos casos.
Desde consultas directamente en el explorador de API hasta la gestión de roles y permisos, una herramienta poderosa que tomaría muchas horas de trabajo desarrollarla de forma independiente.
Las acciones nos permiten ejecutar una función predefinida, generalmente fuera de la lógica de negocio de la aplicación, muy similar a lo que hacen los eventos, enviar llamadas a funciones serverless u otros endpoints externos pero automáticamente después de la ocurrencia de un evento en la base de datos.
Quizá te puedan interesar
Hemos visto las funcionalidades básicas para gestionar nuestros datos que GraphQL nos ofrece. Las …
leer másEn el capítulo anterior veíamos cómo crear un proyecto con Hasura y Docker en cuestión de minutos, …
leer másGraphQL es un lenguaje de consultas y manipulación de datos de código abierto para datos nuevos o …
leer másDe concepto a realidad