GraphQL es un lenguaje de consultas y manipulación de datos de código abierto para datos nuevos o existentes. Fue desarrollado inicialmente por Facebook en 2012 antes de hacerse de código abierto en 2015.
Hasura nos permite construir APIs modernas basadas en GraphQL de forma rápida y fácil. Nos proporciona también una serie de herramientas por defecto que nos facilitarán tanto el proceso de creación como el de gestión y despliegue de la infraestructura. Puede ejecutarse en un servidor propio (auto hosteado) o en la nube.
Docker es una plataforma de código abierto que permite el despliegue de aplicaciones dentro de contenedores virtuales, lo utilizaremos para ejecutar Hasura y PostgreSQL como base de datos para las pruebas.
Hasura (GraphQL) virtualizado con Docker
Descarga, instalación y ejecución de Docker
Lo primero es acceder a su pagina oficial y descargar e instalar la versión correspondiente a nuestro sistema operativo. Una vez instalado lo ejecutamos y comprobamos que se ha procesado correctamente con:
docker
Los ficheros docker-compose son ficheros de configuración que nos permiten definir y ejecutar aplicaciones Docker. En
nuestro caso vamos a utilizar un fichero de configuración provisto por Hasura para desplegarlo junto a PostgreSQL,
comprobamos que el comando funcione correctamente también:
docker-compose
Fichero docker-compose.yaml y virtualización de Hasura junto a PostgreSQL
En la documentación oficial de
Hasura tenemos los pasos a seguir para desplegarlo en Docker, básicamente hay que copiar el
fichero docker-compose.yaml de su Github
en nuestro PC para lanzarlo con el comando docker-compose up -d.
Con docker ps podemos comprobar que ambos contenedores se están ejecutando sin problemas además de ver toda la
información relativa a los mismos, estado, puertos, imágenes, volúmenes, etc.
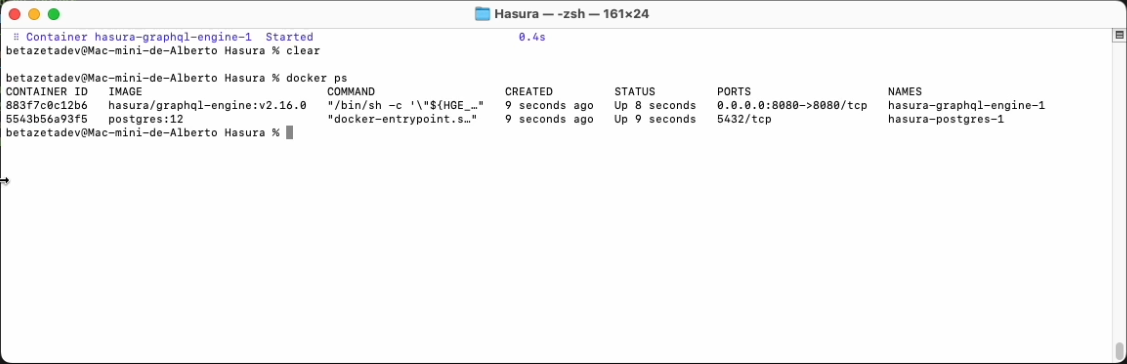
Una vez desplegado podemos acceder a la dirección localhost:8080 desde nuestro navegador web.
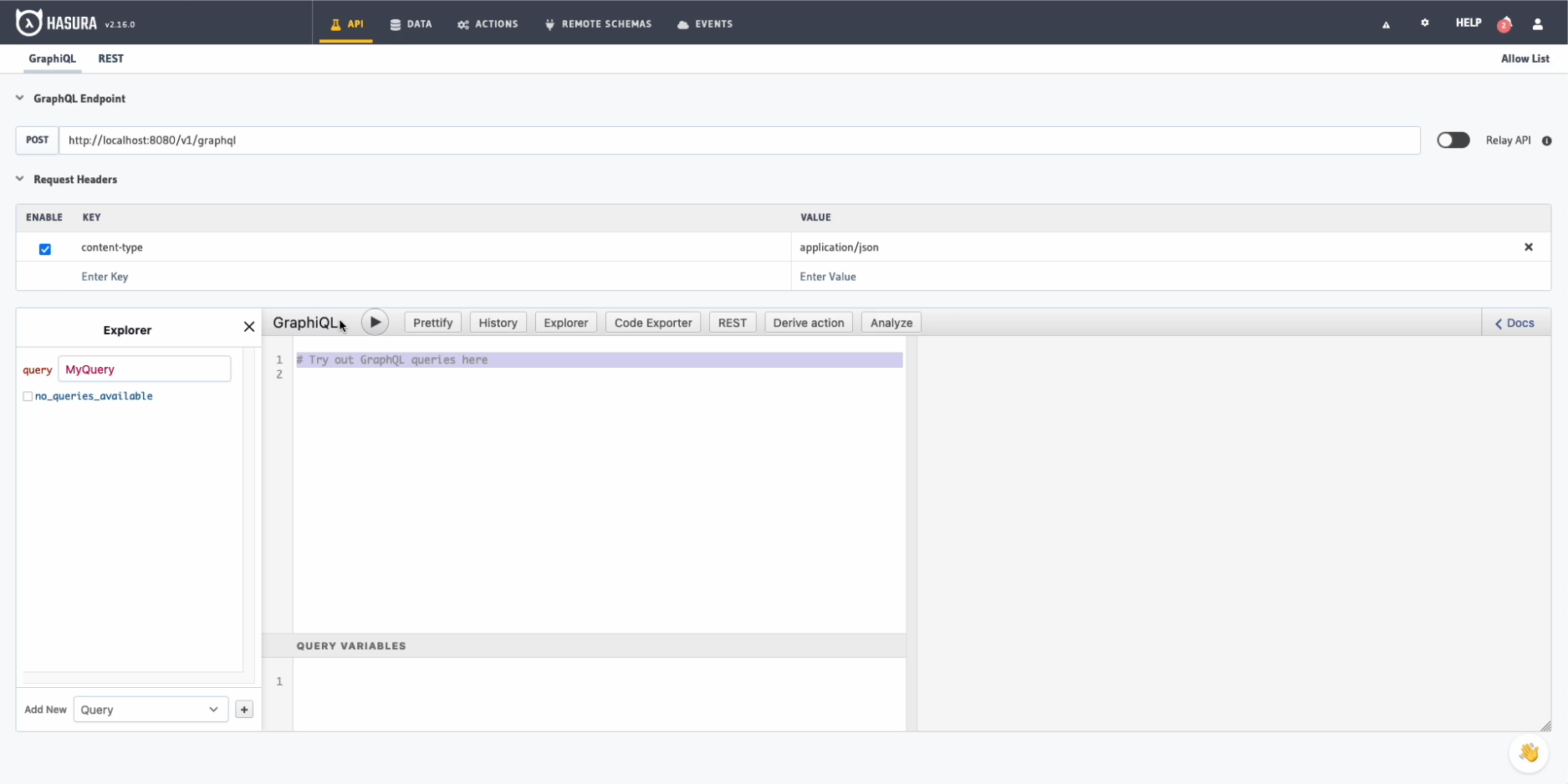
Arriba tenemos diferentes pestañas:
API: Una interfaz gráfica para realizar consultas a nuestra base de datos utilizando la sintaxis de GraphQL.Data: Para gestionar nuestra base de datos, relaciones, permisos, etc.Actions: Llamadas a una tercera API externa.Remote schemas: Conexión con otras bases de datos.Events: Gestión de eventos de nuestra base de datos como inserciones, actualizaciones o borrados, los clásicos triggers.Monitoring: Monitorización de nuestra API, accesos, errores y demás.
Creación de la base de datos y acceso a los mismos
Ahora que ya tenemos Hasura corriendo es hora de conectar nuestra base de datos y crear alguna tabla para insertar datos
y poder realizar consultas desde la interfaz gráfica de Hasura.
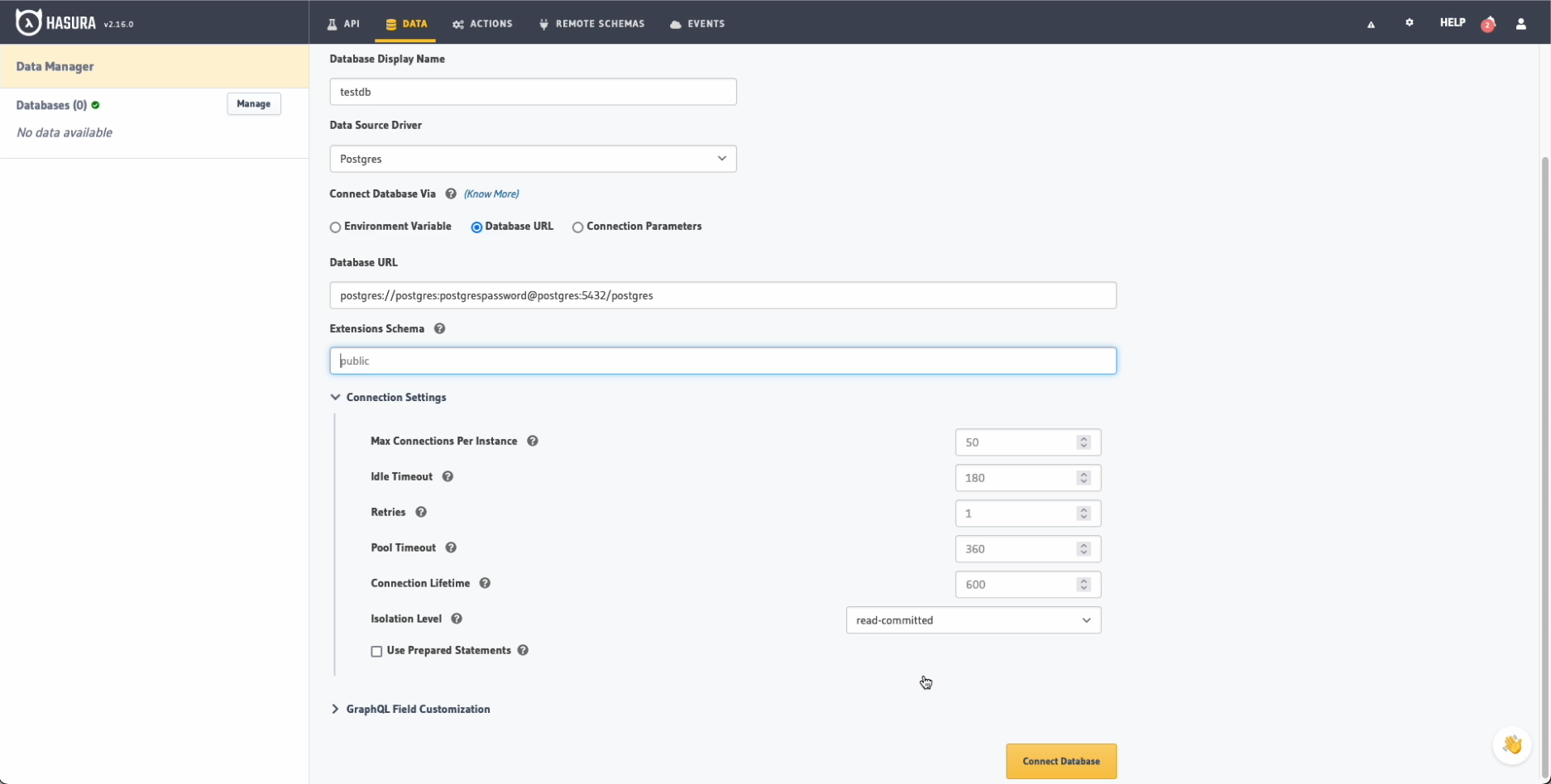
Desde la pestaña Data podemos crear una nueva base de datos, en nuestro caso la llamaremos testdb y la conectaremos
utilizando la URL de conexión configurada en el fichero docker-compose.yaml del principio:
postgres://postgres:postgrespassword@postgres:5432/postgres
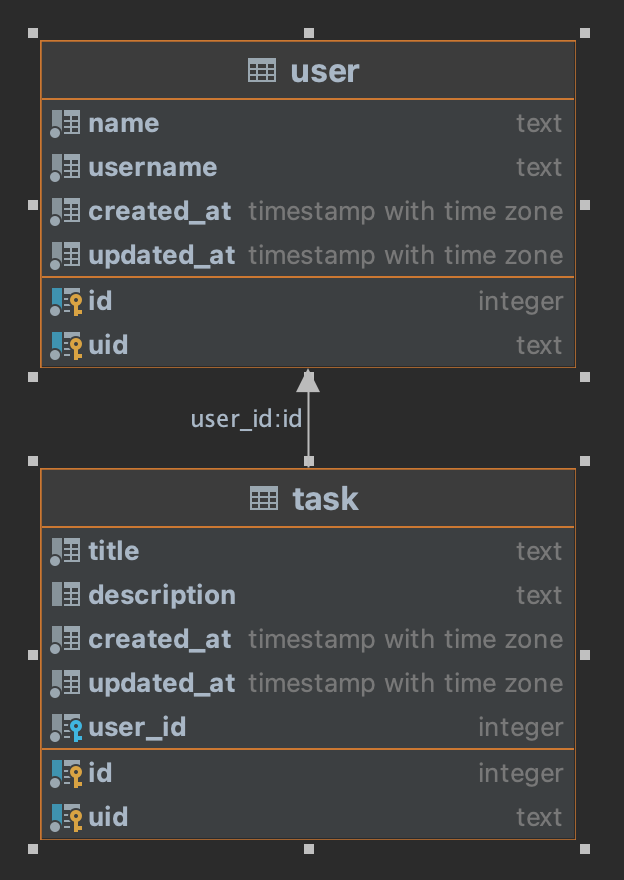
En este ejemplo crearemos una base de datos con dos tablas user y task con la única peculiaridad de que la
tabla task está relacionada con la de user mediante el campo user_id para poder saber a quién pertenece cada
tarea y jugar un poco con los filtrados y las diferentes formas de recoger los datos según el caso de uso.
Usando el Hasura UI podemos insertar nuevos datos en nuestra base de datos, la pestaña Insert row dentro de Data nos
permite hacerlo fácilmente y rápido. Podríamos necesitar crear un usuario primero para poder crear tareas para él si ya
hemos creado las restricciones de la relación.
Tras insertar nuestros datos podemos entrar en la pestaña API para empezar a hacer consultas, en el ejemplo yo sólo
he creado un usuario con dos tareas asignadas para las pruebas pero lógicamente cuánto mayor sea la cantidad de datos
más interesantes y útiles serán las consultas que podamos realizar.
GraphQL es un lenguaje de consulta y manipulación de datos para APIs, y un entorno de ejecución para realizar consultas
con datos existentes (o nuevos), nos proporciona tres tipos de operaciones, query (consulta), mutation (inserción)
y subscription (consulta en tiempo real), en este caso utilizaremos sólo las queries a modo de ejemplo, las
veremos en profundidad en otro artículo.
Podemos consultar todas las tareas:
query AllTasks {
task {
id
title
description
}
}
Podemos consultar todas las tareas con el usuario al que pertenece cada una:
query AllTasksWithUser {
task {
id
title
description
user {
id
name
}
}
}
O aquellas tareas con un título igual a un texto introducido:
query TasksByTitle {
task(where: {title: {_similar: "Task title"}}) {
id
title
description
user {
id
name
}
}
}
Pero no sólo eso, además también podemos ordenarlas por fecha de creación (descendiente en este caso):
query TasksByTitleOrderDesc {
task(order_by: {created_at: desc}) {
id
title
description
user {
id
name
}
}
}
Si tenemos indexada la relación entre usuario y tarea (pulsando en Track a la relación entre ambos dentro de Data)
podemos directamente recoger a través de un usuario todas sus notas en vez de tener que obtenerlos de cada nota
individualmente:
query UsersTasks {
user {
id
name
tasks {
id
title
description
}
}
}
Podemos observar que la diferencia con las clásicas API REST es que en este caso quién determina los datos a obtener es el propio cliente y no el servidor, mientras REST se basa en peticiones estáticas predefinidas por el servidor, GraphQL ofrece por defecto los datos que pueden llegar ser necesarios y el cliente solicitará aquellos que realmente necesite.
Esto es muy útil para optimizar el tráfico de datos y no sobrecargar la red con información que no se va a utilizar, puede que para un menú sólo necesitemos el título de una tarea sin embargo para mostrarla la información completa, solicitaremos en cada caso los datos estrictamente necesarios, es decisión del cliente.
Como todo, hacerlo de esta forma tiene sus convenientes e inconvenientes, es cuestión de conocerlo y tener alternativas con las que poder facilitarnos el trabajo y adaptarnos a las necesidades de cada proyecto.
Puedes ver todo el proceso en vídeo desde nuestro canal de Youtube.
En el próximo capítulo veremos en profundidad las diferentes operaciones (query, mutation, subscription) que
GraphQL nos ofrece para poder gestionar nuestros datos a través de la API. En
su especificación tienes toda la información necesaria.
Conclusiones
Hemos visto cómo crear una API GraphQL utilizando Hasura y Docker, añadido y consultado datos en cuestión de minutos.
Para un proyecto en el que sea necesario tener un producto mínimo viable (MVP) de forma rápida para simplemente tantear el
mercado es una idea a tener en cuenta por su flexibilidad y potencia.
Relacionado
- Parte 2: https://betazeta.dev/es/blog/docker-hasura-graphql-2/
- Parte 3: https://betazeta.dev/es/blog/docker-hasura-graphql-3/
- Docker: https://www.docker.com/
- Docker Compose: https://docs.docker.com/compose/
- GraphQL: https://graphql.org/
- Especificación GraphQL: https://spec.graphql.org/draft/
- PostgreSQL: https://www.postgresql.org/
- Hasura: https://hasura.io/


