En el capítulo anterior veíamos cómo crear un proyecto con Hasura y Docker en
cuestión de minutos,
con docker-compose up -d hemos lanzado una API GraphQL lista para utilizar a partir de la configuración del
fichero docker-compose indicado en
la documentación oficial de Hasura.
Principalmente GraphQL especifica tres clases de operaciones:
- Query: Solicitar datos.
- Mutation: Crear, actualizar o eliminar.
- Subscription: Gestión en tiempo real.
GraphQL
Query
Las query (consulta) son la forma más común de interacción con una API GraphQL. Como una consulta de las clásicas bases de datos nos permite obtener información del servidor, en este caso a través de la API previamente expuesta en condiciones de seguridad. Hasura nos permite gestionar roles y permisos para limitar la información que se expone pero eso lo veremos en otro capítulo.
Podemos por ejemplo obtener los id (ID interno), title (Título) y created_at (Fecha de creación) de todas las tareas con la query:
SOLICITUD
query AllTasksQuery{
task {
id
title
created_at
}
}
RESPUESTA
{
"data": {
"task": [
{
"id": 8,
"title": "Limpiar la casa",
"created_at": "2022-11-30T11:20:46.148+00:00"
},
{
"id": 12,
"title": "Crear una lista de tareas",
"created_at": "2022-12-13T00:31:17.686201+00:00"
},
{
"id": 10,
"title": "Escribir un informe",
"created_at": "2022-07-17T00:10:33.29+00:00"
},
...
]
}
}
También podemos establecer un límite de dos tareas con la opción limit:
SOLICITUD
query AllTasksQuery{
task(limit: 2) {
id
title
created_at
}
}
RESPUESTA
{
"data": {
"task": [
{
"id": 8,
"title": "Limpiar la casa",
"created_at": "2022-11-30T11:20:46.148+00:00"
},
{
"id": 12,
"title": "Crear una lista de tareas",
"created_at": "2022-12-13T00:31:17.686201+00:00"
}
]
}
}
Nos devuelve las dos primeras tareas de la base de datos, consulta que podemos combinar con una operación de ordenación por fecha.
SOLICITUD
query LimitedTasksQuery{
task(limit: 2, order_by: {created_at: desc}) {
id
title
created_at
}
}
RESPUESTA
{
"data": {
"task": [
{
"id": 19,
"title": "Comprar polvorones",
"created_at": "2022-12-13T01:29:53.106341+00:00"
},
{
"id": 17,
"title": "Visitar a la familia",
"created_at": "2022-12-13T01:28:04.622421+00:00"
}
]
}
}
El parámetro where nos permite filtrar los resultados de la consulta, en este caso por ejemplo recibiremos únicamente
aquellas tareas creadas después del 1 de diciembre de 2022:
SOLICITUD
query FilteredTasksQuery{
task(where: {created_at: {_gt: "2022-12-01"}}) {
id
title
created_at
}
}
RESPUESTA
{
"data": {
"task": [
{
"id": 12,
"title": "Crear una lista de tareas",
"created_at": "2022-12-13T00:31:17.686201+00:00"
},
{
"id": 13,
"title": "Bajar al perro",
"created_at": "2022-12-13T01:13:49.136216+00:00"
},
{
"id": 14,
"title": "Hacer deporte",
"created_at": "2022-12-13T01:16:35.274353+00:00"
},
...
]
}
}
Cada una de las funcionalidades ofrecidas por GraphQL pueden ser combinadas entre sí para ajustar la respuesta del servidor a las necesidades del cliente, en este caso le añadimos una ordenación por fecha de creación ascendente:
SOLICITUD
query FilteredTasksQuery{
task(order_by: {created_at: asc}, where: {created_at: {_gt: "2022-12-01"}}) {
id
title
created_at
}
}
RESPUESTA
{
"data": {
"task": [
{
"id": 7,
"title": "Planificar una fiesta",
"created_at": "2022-12-03T05:45:22.096+00:00"
},
{
"id": 5,
"title": "Crear un presupuesto",
"created_at": "2022-12-06T10:28:59.551+00:00"
},
{
"id": 1,
"title": "Hacer una lista de la compra",
"created_at": "2022-12-09T01:37:55.790089+00:00"
},
...
]
}
}
Podemos también filtrar variables por texto por ejemplo recogiendo todas las tareas cuyo usuario de creación coincida con un nombre específico:
SOLICITUD
query FilteredTasksQuery{
task(where: {user: {name: {_eq: "Alfred"}}}) {
user {
name
}
id
title
created_at
}
}
RESPUESTA
{
"data": {
"task": [
{
"user": {
"name": "Alfred"
},
"id": 12,
"title": "Crear una lista de tareas",
"created_at": "2022-12-13T00:31:17.686201+00:00"
},
{
"user": {
"name": "Alfred"
},
"id": 7,
"title": "Planificar una fiesta",
"created_at": "2022-12-03T05:45:22.096+00:00"
},
{
"user": {
"name": "Alfred"
},
"id": 5,
"title": "Crear un presupuesto",
"created_at": "2022-12-06T10:28:59.551+00:00"
},
...
]
}
}
Hasta ahora hemos estado introduciendo los datos directamente en la consulta pero también tenemos la posibilidad de utilizar variables en GraphiQL si pulsamos el símbolo del dólar al lado del parámetro en cuestión.
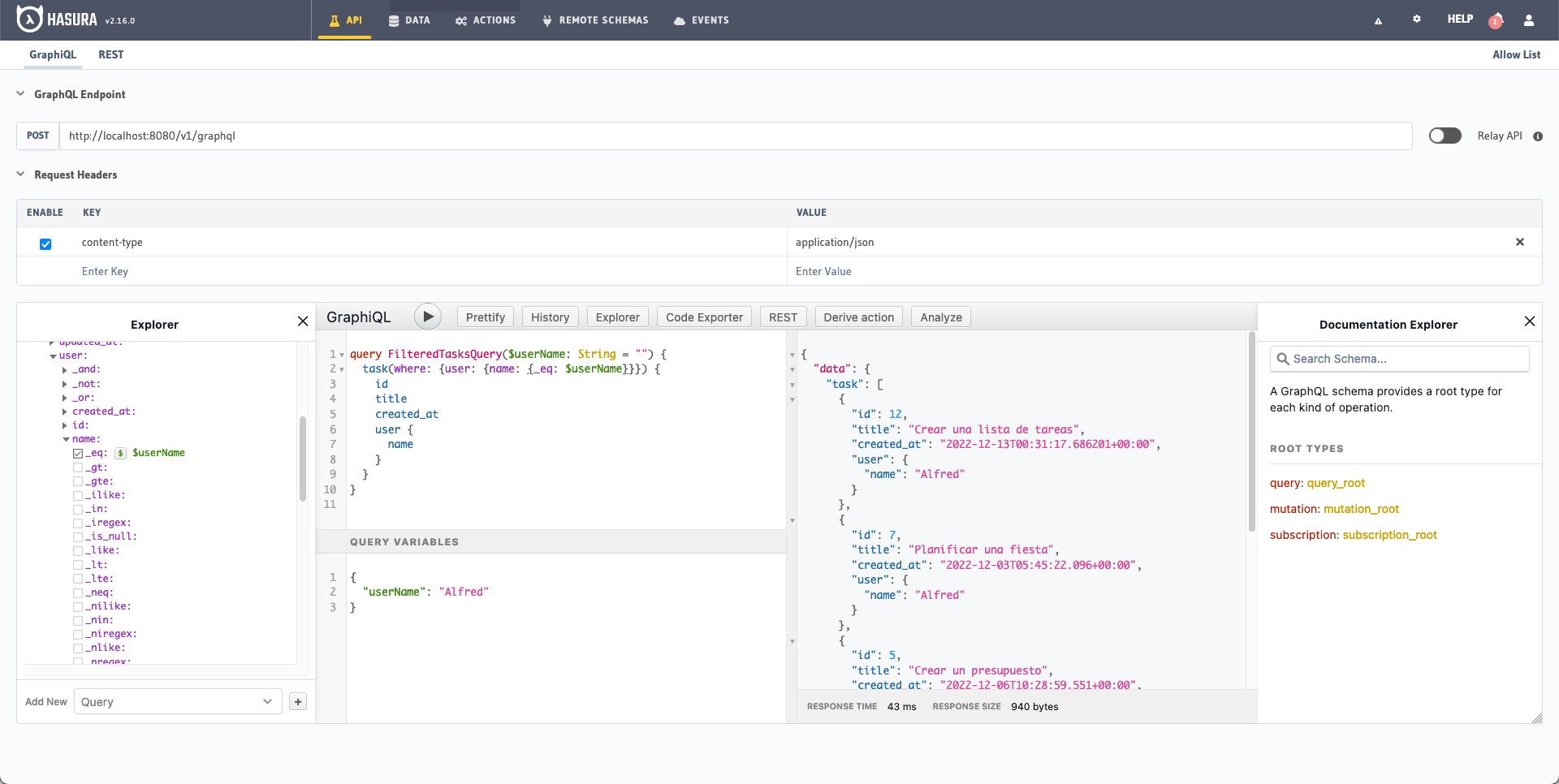
SOLICITUD
query FilteredTasksQuery($userName: String!){
task(where: {user: {name: {_eq: $userName}}}) {
user {
name
}
id
title
created_at
}
}
En el recuadro inferior Query Variables podemos introducir en formato JSON las variables que vayamos a utilizar en la consulta:
VARIABLES
{
"userName": "Alfred"
}
RESPUESTA
{
"data": {
"task": [
{
"user": {
"name": "Alfred"
},
"id": 12,
"title": "Crear una lista de tareas",
"created_at": "2022-12-13T00:31:17.686201+00:00"
},
{
"user": {
"name": "Alfred"
},
"id": 7,
"title": "Planificar una fiesta",
"created_at": "2022-12-03T05:45:22.096+00:00"
},
{
"user": {
"name": "Alfred"
},
"id": 5,
"title": "Crear un presupuesto",
"created_at": "2022-12-06T10:28:59.551+00:00"
},
...
]
}
}
También podemos obtener todas aquellas tareas que contengan la palabra casa en su título:
SOLICITUD
query FilteredTasksQuery{
task(where: {title: {_like: "%casa%"}}) {
id
title
created_at
}
}
RESPUESTA
{
"data": {
"task": [
{
"id": 8,
"title": "Limpiar la casa",
"created_at": "2022-11-30T11:20:46.148+00:00"
}
]
}
}
El offset nos permite saltarnos un número de resultados, por ejemplo para obtener las tareas empezando a partir de la
tercera nos saltamos las dos primeras:
SOLICITUD
query FilteredTasksQuery{
task(offset: 2) {
id
title
created_at
}
}
RESPUESTA
{
"data": {
"task": [
{
"id": 10,
"title": "Escribir un informe",
"created_at": "2022-07-17T00:10:33.29+00:00"
},
{
"id": 13,
"title": "Bajar al perro",
"created_at": "2022-12-13T01:13:49.136216+00:00"
},
{
"id": 14,
"title": "Hacer deporte",
"created_at": "2022-12-13T01:16:35.274353+00:00"
},
...
]
}
}
Mutation
En GraphQL una mutation es una operación que permite modificar los datos del servidor. Es similar a una consulta pero en lugar de obtener datos (más allá de los recién creados), realiza una acción que modifica algún aspecto del estado del servidor.
Para agregar un nuevo usuario o una tarea podemos utilizar las siguientes mutation.
En esta primera llamada añadimos un nuevo usuario introduciendo los parámetros directamente en la consulta:
MODIFICACION
mutation InsertUserMutation {
insert_user(objects: {
uid: "25d4c7b0-1b5a-4b9e-8c5a-2c7f3a7478e9",
username: "monique",
name: "Monique"}) {
affected_rows
returning {
id
name
}
}
}
RESPUESTA
{
"data": {
"insert_user": {
"affected_rows": 1,
"returning": [
{
"id": 10,
"name": "Monique"
}
]
}
}
}
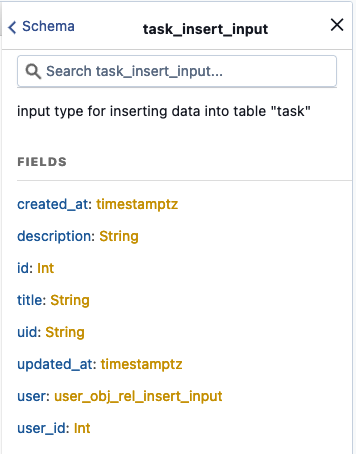
Y esta otra para insertar una nueva tarea utilizando variables. En nuestro ejemplo la clase task_insert_input es generada por
Hasura automáticamente y define los campos que podemos utilizar para insertar una nueva tarea.
MODIFICACION
mutation InsertTaskMutation($objects: [task_insert_input!] = {}) {
insert_task(objects: $objects) {
affected_rows
returning {
id
title
created_at
}
}
}
Pasándole de nuevo los parámetros mediante variables en formato JSON:
VARIABLES
{
"objects": {
"title": "Escribir un artículo",
"uid": "486a4252-6576-45d3-bc9a-1d6f0388b581",
"user_id": 6
}
}
RESPUESTA
{
"data": {
"insert_task": {
"affected_rows": 1,
"returning": [
{
"id": 21,
"title": "Escribir un artículo",
"created_at": "2022-12-20T22:30:23.434237+00:00"
}
]
}
}
}
En el panel derecho de Hasura llamado Documentation Explorer encontramos la documentación generada para ver
los campos requeridos por nuestras consultas, por ejemplo la clase task_insert_input del ejemplo:
Subscription
Las subscription (subscripción) nos sirven para comunicarnos en tiempo real y de forma bidireccional con el servidor, actualizando la información en los clientes inmediatamente. Utiliza la tecnología WebSockets para mantener un canal abierto y así poder comunicarse sin tener que iniciar de nuevo la conexión.
Su uso excesivo puede llegar a provocar un gran consumo de recursos y dependiendo la casuística del proyecto pueden no ser necesarias o añadir complejidad a la implementación. Siguiendo con el ejemplo, podríamos crear una subscripción para tener la lista de usuarios actualizados en tiempo real:
subscription AllUsersSubscription {
user {
id
name
}
}
También podemos utilizar los filtrados y ordenaciones como en este ejemplo para obtener las tareas de todos los usuarios
con nombre Bob:
subscription BobTasksSubscription {
task(where: {user: {name: {_eq: "Bob"}}}) {
id
title
created_at
}
}
Para ver los resultados de las subscripciones en vivo te recomiendo el vídeo de un poco más adelante.
Los Fragment no son operaciones como tal pero no está de más mencionarlos ya que suelen acompañar a estas operaciones porque nos permiten reutilizar partes de las consultas y crear una especie de plantillas para no repetir código y simplificar así la organización.
Estas son las operaciones básicas que podemos realizar con GraphQL, para ver los Fragment, tipos de datos personalizados
y otros detalles todo está definido a la perfección en la especificación oficial.
Conclusiones
A mi parecer se trata de un lenguaje con una sintaxis bastante sencilla pero con una flexibilidad a la hora de diseñar y estructurar las consultas espectacular que nos permite crear aplicaciones de una forma rápida y eficiente. Como siempre, todo depende de las necesidades de cada proyecto. Conociéndolo ya sabemos si nos puede ser útil o no y cómo afrontar su implementación.
Relacionado
- Parte 1: https://betazeta.dev/es/blog/docker-hasura-graphql/
- Parte 3: https://betazeta.dev/es/blog/docker-hasura-graphql-3/
- GraphQL: https://graphql.org/
- Especificación GraphQL: https://spec.graphql.org/draft/