En esta serie hemos explorado diversos motores de bases de datos, como SQLite, y los conceptos fundamentales del modelo relacional. Ahora, profundizaremos en PostgreSQL, un sistema de gestión de bases de datos relacional (RDBMS) de código abierto ampliamente reconocido por su robustez, escalabilidad y extensibilidad. Diseñado para aplicaciones complejas, combina una arquitectura cliente-servidor con un soporte avanzado para múltiples usuarios y funcionalidades especializadas. Su versatilidad lo convierte en una opción ideal tanto para proyectos empresariales como para desarrollos personales.
Al igual que otros motores relacionales como SQLite, PostgreSQL utiliza el lenguaje SQL (Structured Query Language) para
interactuar con los datos. Sin embargo, se diferencia por incluir características avanzadas como soporte para
JSON/JSONB, extensiones modulares, y una gestión eficiente de concurrencia. Esto lo hace adecuado para aplicaciones
que
requieren flexibilidad, alta disponibilidad y manejo eficiente de grandes volúmenes de datos.
En este artículo, configuraremos PostgreSQL en un entorno virtualizado utilizando Docker y diseñaremos una base de datos que modele una red de transporte. Este ejercicio práctico incluirá relaciones Uno-a-Uno, Uno-a-Muchos y Muchos-a-Muchos, lo que permitirá poner en práctica conceptos fundamentales del modelo relacional mientras exploramos las capacidades de PostgreSQL. Además, sentaremos las bases para futuras exploraciones de sus funcionalidades avanzadas.
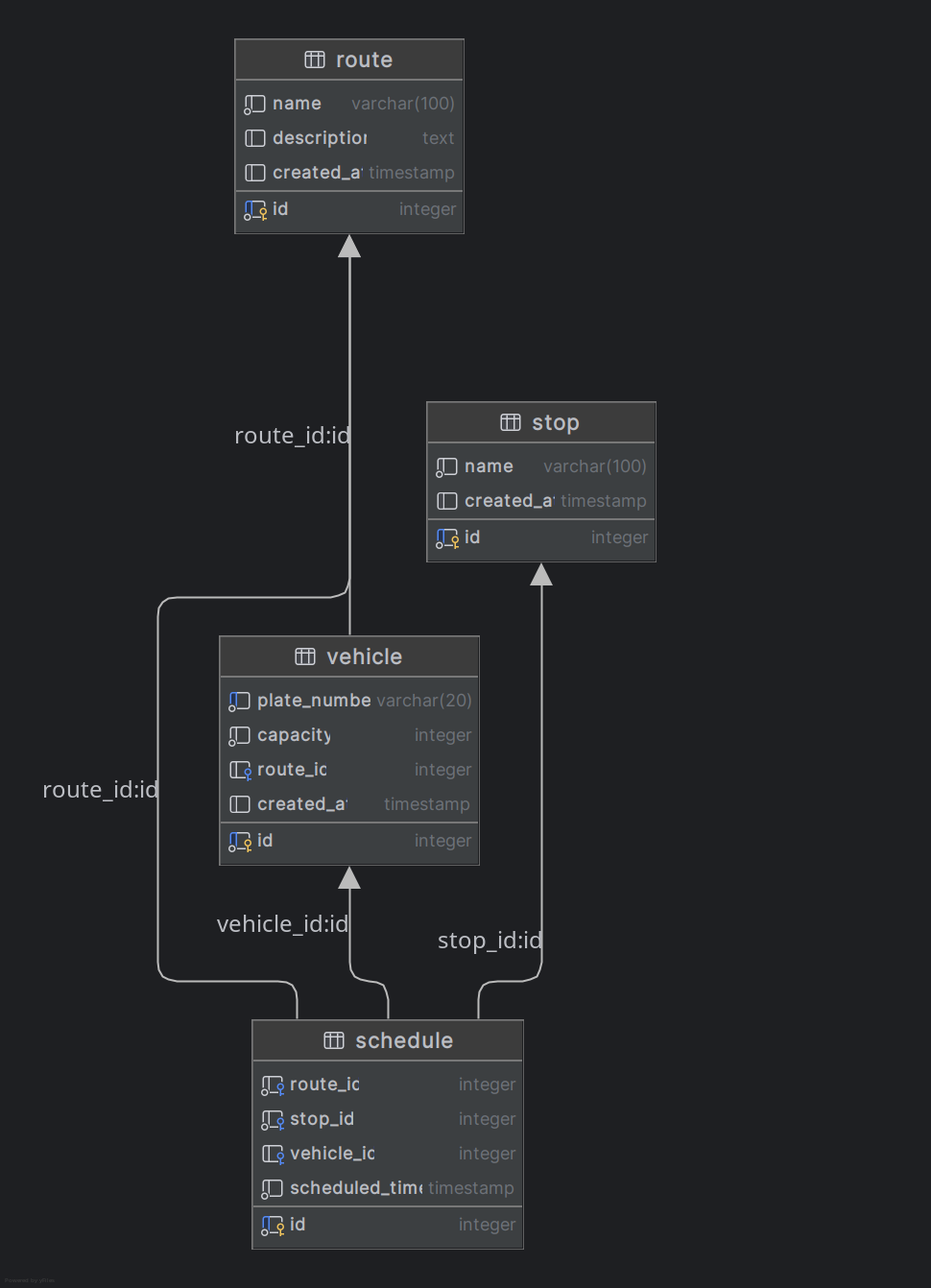
- Route: Define las rutas que operan dentro de la red de transporte.
- Stop: Lista las paradas incluidas en las rutas.
- Vehicle: Contiene información sobre los vehículos que operan en las rutas.
- Schedule: Tabla intermedia que gestiona los horarios asignados a las rutas y paradas específicas.
Ejecución en Docker
Para ejecutar PostgreSQL en un entorno local y conectarte con un cliente de gestión de bases de datos como DBeaver o PgAdmin, puedes utilizar Docker. Esto te permitirá tener, de forma fácil, un entorno limpio y controlado sin necesidad de instalar PostgreSQL directamente en tu sistema.
Ejecuta el siguiente comando para crear y lanzar un contenedor con PostgreSQL:
docker run --name postgres-transport -e POSTGRES_PASSWORD=secret -d -p 5432:5432 postgres
Si no estás familiarizado con Docker, puedes revisar nuestra serie al respecto desde el punto en que más cómodo te encuentres y después regresar a este punto. Aun así, este comando hará lo siguiente:
- Descargar la imagen oficial de PostgreSQL (si aún no la tienes en tu máquina).
- Crear un contenedor llamado postgres-transport.
- Configurar la contraseña del usuario administrador postgres como secret.
- Exponer el puerto 5432, que es el puerto predeterminado de PostgreSQL, para que puedas conectarte desde herramientas externas.
Conexión desde un cliente SQL
Una vez que el contenedor esté en ejecución, puedes usar un cliente SQL para conectarte a la base de datos. Estas son las credenciales necesarias:
Host: localhost
Puerto: 5432
Usuario: postgres
Contraseña: secret
Base de datos: postgres (base de datos predeterminada)
En este ejemplo utilizaremos DBeaver como cliente SQL, pero puedes usar cualquier otro cliente que prefieras. Para conectarte a la base de datos, sigue estos pasos:
- Descarga e instala DBeaver desde su sitio web oficial.
- Abre DBeaver y selecciona PostgreSQL como el tipo de conexión.
- Introduce las credenciales de conexión que hemos mencionado anteriormente.
- Sigue el asistente para configurar la conexión.
Una vez conectado, podemos utilizar la interfaz gráfica de DBeaver para gestionar nuestra base de datos, añadir, modificar y eliminar tablas además de ejecutar consultas SQL entre otras cosas.
Diseño de la base de datos
El modelo está compuesto por cuatro tablas principales: Route, Stop, Vehicle y Schedule. Cada tabla tiene
claves primarias y relaciones bien definidas para garantizar la integridad referencial. Puedes abrir el diálogo de
creación
de tabla en DBeaver con el botón derecho sobre
Tabla: Route
| Campo | Tipo de dato | Restricciones | Descripción |
|---|---|---|---|
| id | SERIAL | PRIMARY KEY | Identificador único de la ruta |
| name | VARCHAR(100) | NOT NULL | Nombre de la ruta |
| description | TEXT | NULL | Descripción de la ruta |
| created_at | TIMESTAMP | DEFAULT NOW() | Fecha de creación de la ruta |
Tabla: Stop
| Campo | Tipo de dato | Restricciones | Descripción |
|---|---|---|---|
| id | SERIAL | PRIMARY KEY | Identificador único de la parada |
| name | VARCHAR(100) | NOT NULL | Nombre de la parada |
| created_at | TIMESTAMP | DEFAULT NOW() | Fecha de creación de la parada |
Tabla: Vehicle
| Campo | Tipo de dato | Restricciones | Descripción |
|---|---|---|---|
| id | SERIAL | PRIMARY KEY | Identificador único del vehículo |
| plate_number | VARCHAR(20) | UNIQUE NOT NULL | Matrícula del vehículo |
| capacity | INT | NOT NULL, CHECK (capacity > 0) | Capacidad máxima de pasajeros |
| route_id | INT | FOREIGN KEY REFERENCES route(id) | Ruta asignada al vehículo |
| created_at | TIMESTAMP | DEFAULT NOW() | Fecha de creación del registro del vehículo |
Tabla: Schedule
| Campo | Tipo de dato | Restricciones | Descripción |
|---|---|---|---|
| id | SERIAL | PRIMARY KEY | Identificador único del horario |
| route_id | INT | NOT NULL, FOREIGN KEY REFERENCES route(id) ON DELETE CASCADE | Ruta del horario |
| stop_id | INT | NOT NULL, FOREIGN KEY REFERENCES stop(id) ON DELETE CASCADE | Parada del horario |
| vehicle_id | INT | FOREIGN KEY REFERENCES vehicle(id) ON DELETE SET NULL | Vehículo asignado al horario |
| scheduled_time | TIMESTAMP | NOT NULL | Hora programada |
Resumen de relaciones
- Uno-a-Muchos:
Route↔Stop: Una ruta puede incluir múltiples paradas.Route↔Vehicle: Una ruta puede tener varios vehículos asignados.
- Muchos-a-Muchos:
Schedulegestiona la relación entre rutas y paradas, añadiendo el contexto del tiempo y vehículos.
En PostgreSQL, el tipo de dato SERIAL se utiliza comúnmente para definir columnas que actuarán como identificadores
únicos, o claves primarias, en una tabla. Este tipo de dato simplifica la creación de secuencias auto-incrementales,
permitiendo que los valores en estas columnas se generen automáticamente al insertar nuevos registros.
Cuando defines una columna como SERIAL, PostgreSQL realiza automáticamente tres acciones:
- Crea una secuencia para generar números únicos.
- Asigna esa secuencia como el valor predeterminado de la columna.
- Marca la columna como clave única o primaria si así lo especificas.
A diferencia de otros sistemas como MySQL, donde el auto-incremento está directamente vinculado a la columna, PostgreSQL
crea una secuencia independiente que permite una mayor flexibilidad. Esta secuencia puede ser personalizada,
reutilizada en otras tablas, o ajustada para definir un valor inicial (START WITH) o el incremento entre números (
INCREMENT BY). Además, PostgreSQL ofrece variantes como SMALLSERIAL, SERIAL y BIGSERIAL, que corresponden a los
tipos de datos SMALLINT, INTEGER y BIGINT, respectivamente.
Funcionalidades avanzadas de PostgreSQL
Hasta ahora, hemos explorado cómo diseñar y trabajar con una base de datos relacional en PostgreSQL, aplicando conceptos
fundamentales como la creación de tablas, relaciones entre ellas y el uso de tipos de datos como SERIAL. Este
conocimiento es una excelente base para continuar investigando y experimentando con este potente sistema de gestión de
bases de datos.
PostgreSQL destaca no solo por su robustez y flexibilidad, sino también por su impresionante gama de características avanzadas que lo diferencian de otros sistemas de bases de datos relacionales. Algunas de estas funcionalidades incluyen:
-
JSON y JSONB: La capacidad de almacenar y consultar datos en formato JSON hace que PostgreSQL sea ideal para aplicaciones modernas que manejan datos semiestructurados. Su variante
JSONB(JSON binario) optimiza aún más las búsquedas y operaciones en este tipo de datos. -
Extensiones: Una de las fortalezas únicas de PostgreSQL es su sistema de extensiones, que permite ampliar sus capacidades según las necesidades específicas del proyecto. Extensiones populares como PostGIS (para datos geoespaciales) o pg_trgm (para búsquedas por similitud) lo convierten en una herramienta extremadamente versátil.
-
Funciones avanzadas: PostgreSQL permite la creación de funciones personalizadas y triggers, lo que facilita automatizar procesos y ejecutar lógica de negocio directamente en la base de datos.
-
Soporte para concurrencia: Gracias a su modelo de control de concurrencia multiversión (MVCC), PostgreSQL garantiza transacciones consistentes incluso en entornos con múltiples usuarios.
Aunque no profundizaremos en estas características en este artículo, explorarlas puede abrirte un mundo de posibilidades para tus proyectos. A medida que sigas practicando con los conceptos aprendidos en esta serie, te invitamos a investigar más sobre las funcionalidades que hacen de PostgreSQL una herramienta tan especial. En futuros artículos, ahondaremos en estas y otras capacidades avanzadas de PostgreSQL.
¡Sigue aprendiendo y explorando! PostgreSQL tiene mucho más que ofrecer, pero sobre todo ¡Happy Coding!