
Docker Compose para administración de contenedores
Habiendo explorado los fundamentos de Docker y su poder para desplegar aplicaciones encapsuladas, …
leer másHoy hablaremos de bases de datos, son, muchas veces, la columna vertebral de sistemas informáticos modernos, desde aplicaciones empresariales hasta redes sociales y sistemas de comercio electrónico. Aunque hoy en día damos por sentada su existencia, la tecnología de bases de datos no siempre ha sido tan avanzada y accesible como lo es ahora. De hecho, los primeros sistemas de almacenamiento de datos se desarrollaron en la década de 1960, cuando las necesidades crecientes de las organizaciones empezaron a superar las capacidades de los sistemas tradicionales de archivo en papel y otros métodos físicos de almacenamiento. Con el crecimiento de las empresas y el volumen de información que necesitaban manejar, se hizo evidente la necesidad de una solución digital que permitiera la organización, el almacenamiento y el acceso rápido a grandes cantidades de datos.
Durante sus primeras etapas, los sistemas de bases de datos estaban estructurados de forma jerárquica o en red, permitiendo la organización de datos en estructuras de árbol o gráficos. Aunque estas arquitecturas fueron un gran avance en su momento, también tenían limitaciones importantes, especialmente cuando se trataba de manejar datos complejos y realizar consultas eficientes. En un sistema jerárquico, los datos se almacenaban en una estructura de árbol, donde cada registro tenía un solo “padre”, lo cual limitaba la flexibilidad. Por otro lado, los sistemas de bases de datos en red permitían relaciones más complejas entre datos, pero aún eran difíciles de implementar y mantener, requiriendo a menudo una programación específica para cada aplicación.
Este contexto de innovación y limitaciones técnicas motivó a Edgar F. Codd, un científico informático en IBM, a proponer en 1970 un nuevo modelo de almacenamiento y gestión de datos conocido como “Modelo Relacional”. Codd ideó un sistema en el cual los datos podían almacenarse en tablas, permitiendo su acceso y manipulación mediante un lenguaje de consultas, que más adelante evolucionaría en el lenguaje SQL (Structured Query Language). El modelo relacional no solo permitía almacenar y acceder a grandes volúmenes de información de forma eficiente, sino que también introdujo una flexibilidad sin precedentes para realizar consultas complejas. Este cambio de paradigma impulsó el crecimiento de las bases de datos como las conocemos hoy, sentando las bases para el desarrollo de sistemas de gestión de bases de datos (DBMS) que aún son ampliamente utilizados en la actualidad.
La introducción del modelo relacional revolucionó muchas industrias, permitiendo la creación de aplicaciones empresariales más sofisticadas y promoviendo el uso de datos en la toma de decisiones. Las bases de datos relacionales se convirtieron rápidamente en el estándar para el almacenamiento y la gestión de datos, y su uso se extendió desde la banca y las finanzas hasta la logística y el comercio minorista. Con la llegada de sistemas de gestión de bases de datos como IBM DB2, Oracle y, más adelante, MySQL (MariaDB) y PostgreSQL, entre otras, las empresas tuvieron acceso a potentes herramientas que les permitieron organizar y analizar sus datos de manera eficiente, habilitando nuevas capacidades para gestionar operaciones y procesos a gran escala.
A medida que los datos continúan creciendo en volumen y complejidad, las bases de datos relacionales siguen siendo una tecnología central. Sin embargo, también han surgido nuevas soluciones, como las bases de datos NoSQL, que abordan necesidades específicas que los sistemas relacionales tradicionales no siempre cubren. Además, es común que herramientas como Excel sean usadas como bases de datos de manera informal. Aunque Excel no es una base de datos en sentido estricto, su facilidad de uso y estructura tabular permiten que muchos usuarios lo utilicen para almacenar y organizar datos de forma básica. Este fenómeno ocurre incluso con herramientas como Access, que, siendo un gestor de bases de datos más completo, sigue sin ofrecer la potencia y escalabilidad de un sistema de gestión de bases de datos relacional completo.
A medida que los datos continúan creciendo en volumen y complejidad, las bases de datos relacionales siguen siendo una tecnología clave. Sin embargo, en la actualidad han surgido soluciones más modernas que responden a las demandas de la inteligencia artificial, el análisis en tiempo real y el manejo de datos no estructurados, como las bases de datos NoSQL, que abordan necesidades específicas que los sistemas relacionales tradicionales no siempre cubren.
Las bases de datos relacionales almacenan la información en tablas estructuradas con filas y columnas, permitiendo relaciones complejas entre los datos. Basadas en el modelo relacional propuesto por Edgar F. Codd, su estructura se apoya en el uso de claves primarias y foráneas para vincular los datos entre tablas. Este tipo de base de datos es ideal para aplicaciones donde la integridad de los datos y las transacciones son esenciales, como sistemas financieros, de gestión empresarial o cualquier aplicación que requiera ACID (Atomicidad, Consistencia, Aislamiento y Durabilidad).
Ejemplos: Microsoft SQL (MSSQL), MySQL, PostgreSQL, Oracle.
Las bases de datos documentales son un tipo de base de datos NoSQL que almacenan los datos en documentos, generalmente en formato JSON o BSON. Estos documentos pueden contener datos estructurados y no estructurados y, a diferencia de las bases de datos relacionales, no requieren un esquema fijo. Esto les proporciona una gran flexibilidad, especialmente para manejar datos cambiantes. Las bases de datos documentales son adecuadas para aplicaciones que requieren un acceso rápido a grandes volúmenes de datos no estructurados, como aplicaciones de contenido o sistemas de comercio electrónico.
Ejemplos: MongoDB, Cassandra, CouchDB, Firebase Realtime Database.
Las bases de datos en memoria almacenan los datos directamente en la memoria RAM en lugar de en discos, lo que les permite un acceso mucho más rápido. Son ideales para aplicaciones que necesitan alta velocidad de procesamiento, como juegos en línea, sistemas de transacciones financieras y análisis en tiempo real. Sin embargo, debido a su dependencia de la RAM, pueden tener limitaciones de almacenamiento en comparación con las bases de datos que almacenan en disco.
Las bases de datos de grafos almacenan la información en nodos y aristas, lo que las hace ideales para representar relaciones complejas entre entidades. Este tipo de base de datos es especialmente útil en aplicaciones donde las conexiones entre los datos son tan importantes como los propios datos. Un uso típico de las bases de datos de grafos es en redes sociales, donde se pueden representar las relaciones entre los usuarios, o en sistemas de recomendación y análisis de fraudes.
Ejemplos: Neo4j, Amazon Neptune, ArangoDB.
Existen otros tipos de bases de datos, como las bases de datos de series temporales, las bases de datos de búsqueda y las bases de datos de columnas, cada una diseñada para satisfacer necesidades específicas en términos de rendimiento pero no son las más comunes por lo que no se profundizará en ellas en esta serie. Nos centraremos en los tipos de bases de datos relacionales que son muy utilizadas en la actualidad y las que más desafíos pueden presentar a la hora de definir su estructura.
Las bases de datos relacionales son, probablemente, el tipo de base de datos más utilizado y estudiado en el mundo de la
informática. Desarrolladas en la década de 1970 por Edgar F. Codd, estas bases de datos están basadas en un modelo
estructurado de tablas interrelacionadas, en las que cada tabla representa una entidad o concepto (por ejemplo,
Clientes o Productos). La fortaleza de las bases de datos relacionales radica en su capacidad para mantener la
integridad y consistencia de los datos mediante reglas de normalización y restricciones.
En una base de datos relacional, los datos se organizan en tablas compuestas por filas y columnas. Cada fila representa un registro único (como un cliente específico) y cada columna representa un atributo de ese registro (como el nombre o la dirección del cliente). Estas tablas pueden relacionarse entre sí mediante claves primarias y claves foráneas, permitiendo que los datos se vinculen y consulten en múltiples tablas de forma eficiente.
Por ejemplo, una tabla de Pedidos podría estar vinculada a una tabla de Clientes a través de una clave foránea que
almacena el identificador único del cliente que realizó cada pedido. Esta estructura permite una gran flexibilidad para
realizar consultas y obtener información compleja en una sola operación. Más abajo veremos algún ejemplo más detallado.
Integridad referencial: Una de las principales peculiaridades de las bases de datos relacionales es su capacidad para mantener la integridad de los datos a través de restricciones de claves. La integridad referencial asegura que las relaciones entre tablas sean válidas, es decir, que cada clave foránea en una tabla tenga un correspondiente registro en la tabla de referencia. Esto evita, por ejemplo, que existan pedidos asignados a clientes inexistentes.
ACID: Las bases de datos relacionales suelen cumplir con las propiedades ACID: Atomicidad, Consistencia, Aislamiento y Durabilidad. Estas propiedades son fundamentales en aplicaciones donde es esencial garantizar que las transacciones (como pagos o registros) se completen correctamente.
SQL como lenguaje de consulta: Las bases de datos relacionales utilizan SQL (Structured Query Language) y sus variantes para definir, manipular y consultar los datos. Éste, permite realizar consultas complejas mediante operadores de selección, unión y filtrado, ofreciendo una sintaxis poderosa y flexible para extraer información. Además, SQL ha evolucionado para soportar funciones avanzadas como agregaciones, subconsultas y procedimientos almacenados.
Integridad de los datos: Garantizan que los datos sean consistentes y precisos mediante restricciones de integridad (como claves primarias, claves foráneas y reglas de unicidad). Por ejemplo, en un sistema bancario, las transacciones financieras dependen de la integridad de los datos para asegurar que los saldos de las cuentas sean precisos y no haya duplicación de transacciones.
Capacidad para realizar consultas complejas: Permiten realizar consultas avanzadas y complejas usando SQL, lo cual facilita la extracción de información valiosa. Por ejemplo, en una empresa de comercio electrónico, los analistas pueden usar SQL para obtener información detallada, como el promedio de gasto de los clientes por mes o el inventario de productos más vendidos. La capacidad de realizar uniones (joins) entre múltiples tablas permite que estos sistemas respondan a consultas complejas con rapidez y precisión.
Escalabilidad vertical para grandes volúmenes de datos: Están diseñadas para manejar grandes cantidades de datos y escalar verticalmente (es decir, con hardware más potente). En grandes organizaciones, como un hospital que almacena millones de registros médicos, una base de datos relacional puede gestionarse en un servidor de alto rendimiento que permite procesar, almacenar y recuperar enormes cantidades de datos con eficiencia, garantizando el acceso rápido a la información del paciente.
Acceso concurrente y control de usuarios: Múltiples usuarios pueden acceder y manipular los datos simultáneamente sin conflictos, gracias a los mecanismos de control de concurrencia y permisos. Por ejemplo, en un sistema de gestión de proyectos, varios empleados pueden actualizar información en tiempo real sobre el estado de diferentes tareas sin que los datos se corrompan. Además, el administrador puede definir permisos de acceso, asegurando que solo los usuarios autorizados puedan ver o modificar datos sensibles.
Estándar ampliamente adoptado y compatible: SQL es un estándar ampliamente aceptado y compatible, lo que facilita la migración de datos y la interoperabilidad entre diferentes sistemas de bases de datos relacionales. Por ejemplo, una empresa que decide cambiar su sistema de gestión de datos de MySQL a PostgreSQL puede migrar los datos y las consultas con relativa facilidad debido a la compatibilidad de SQL entre estas plataformas. Este estándar también permite que desarrolladores y analistas se adapten rápidamente a nuevos sistemas sin necesidad de reaprender un lenguaje de consulta diferente.
Aun con todas sus muchas ventajas, las bases de datos relacionales también tienen algunas limitaciones. Por ejemplo:
Escalabilidad limitada: Suelen estar diseñadas para escalar verticalmente, lo que implica aumentar la capacidad de un único servidor para gestionar más datos o usuarios. Esto puede resultar costoso y complicado en comparación con sistemas NoSQL, que permiten una escalabilidad horizontal más sencilla mediante la adición de múltiples servidores.
Rigidez del esquema: La estructura de datos es rígida y requiere un esquema predefinido. Esto significa que cambios en la estructura, como agregar nuevas columnas o modificar el tipo de datos, pueden ser complejos y requerir tiempo de inactividad. Este diseño estructurado limita la adaptabilidad en entornos donde los datos cambian rápidamente.
Rendimiento bajo con grandes volúmenes de datos no estructurados: No están optimizadas para manejar grandes volúmenes de datos no estructurados (como texto libre, multimedia o datos generados por IoT), lo que puede afectar significativamente el rendimiento en este tipo de aplicaciones. Bases de datos NoSQL suelen ser más adecuadas para estos casos.
Alta carga de mantenimiento: Requieren una administración constante para garantizar el rendimiento, la seguridad y la integridad de los datos. Configuraciones como índices, permisos y copias de seguridad necesitan gestión regular, lo que implica costos de mantenimiento y recursos técnicos especializados.
Complejidad en consultas distribuidas: Realizar consultas y transacciones distribuidas entre varias bases de datos relacionales es complicado y puede degradar el rendimiento. En aplicaciones distribuidas o sistemas de alta disponibilidad, gestionar transacciones distribuidas de manera eficaz es más complejo y requiere configuraciones avanzadas o incluso el uso de herramientas externas para sincronización y consistencia.
A pesar de estas limitaciones, las bases de datos relacionales siguen siendo una opción popular y efectiva para muchas aplicaciones empresariales y de misión crítica. Su capacidad para garantizar la integridad de los datos, su flexibilidad en consultas y su amplio soporte en la industria las convierten en una opción sólida para una amplia variedad de casos de uso. En su esencia, utilizan el modelo relacional que se define por la estructura de tablas y la relación entre ellas, organizando los datos de manera que sean coherentes y fácilmente accesibles.
Veamos ahora en los conceptos fundamentales que sustentan las bases de datos relacionales y cómo se aplican en la práctica.
Las entidades representan los conceptos principales sobre los cuales se almacenará información en la base de datos. Cada entidad se define en una tabla, que es la estructura fundamental para organizar los datos. Una tabla consta de filas y columnas:
Cliente, cada fila contendría los datos de un cliente individual.nombre, dirección o
correo electrónico en la tabla Cliente.Existe mucha discusión sobre si las tablas deben nombrarse en plural o en singular; por ejemplo, usar Cliente o
Clientes. La elección dependerá de la convención seguida en el proyecto o en la organización. Personalmente,
prefiero nombrar las tablas en singular, considero que, cada fila representa una única entidad, no un conjunto de
ellas. Este enfoque también facilita la coincidencia del nombre de la tabla con el de la clase cuando se utiliza un *
ORM* (Object Relational Mapping), lo cual aporta consistencia y claridad al código.
Un ORM es una herramienta que permite mapear las tablas de la base de datos a objetos en el código, facilitando la tarea de interactuar con la base de datos desde la aplicación. Algunos ejemplos de ORMs populares son Hibernate para Java, Room para Android, Entity Framework para .NET y Sequelize para Node.js.
Es fundamental mantener la coherencia en el uso de nombres para evitar confusiones, y, siempre que sea posible, utilizar nombres en inglés, ya que es el idioma “estándar” en programación y facilita la colaboración con desarrolladores de todo el mundo de ser necesario.
Una de las características más importantes de las bases de datos relacionales es la capacidad de establecer relaciones entre diferentes tablas, lo que permite organizar y asociar datos de manera significativa. Las relaciones más comunes en una base de datos relacional incluyen:
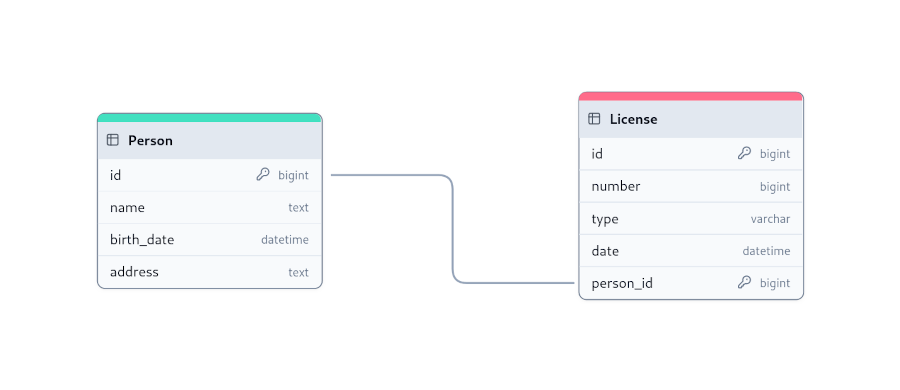
Person y una tabla License, donde cada persona tiene una única licencia y cada
licencia está asociada a una sola persona. Se restringe la clave foránea en la tabla referenciada para que sea única,
garantizando así que la relación sea de uno a uno. Sólo una persona puede tener una licencia y sólo una licencia puede
pertenecer a una persona.Customer) puede realizar varios
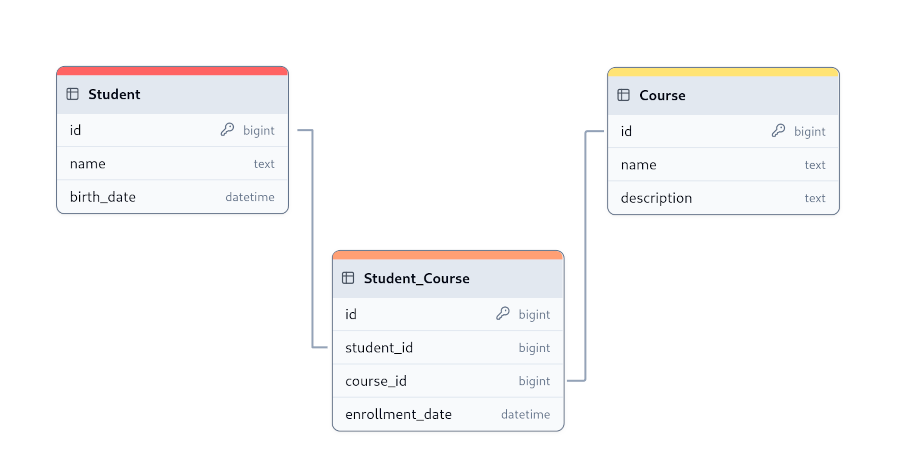
pedidos (en la tabla Order), estableciendo una relación uno a muchos entre Customer y Order.Student y una tabla Course, donde un
estudiante puede inscribirse en varios cursos, y un curso puede tener varios estudiantes. Para gestionar estas
relaciones, se crea una tabla intermedia, como Student_Course, que contiene referencias a las claves primarias
de Student y Course.Los ejemplos aquí presentados son simplificados y variarán dependiendo de la complejidad de la aplicación y de los requisitos de los datos, por lo general cada una de los ejemplos aquí expuestos contendrían una mayor cantidad de campos y tablas relacionadas. Es importante tener en cuenta que la estructura de la base de datos debe reflejar fielmente la realidad del dominio del problema que se está resolviendo.
Para gestionar estas relaciones, las bases de datos relacionales utilizan claves primarias y claves foráneas:
Clave Primaria (Primary Key): es un identificador único para cada registro en una tabla. La clave primaria
garantiza que cada fila de una tabla sea única. Por ejemplo, en la tabla Customer, el campo id puede
servir, y suele utilizarse como clave primaria. Aunque recientemente se ha popularizado el uso de UUIDs (Universal
Unique Identifiers) como claves primarias, ya que son únicos a nivel global y no dependen de la base de datos para ser
generados, tampoco tienen los límites de tamaño que tienen los enteros y son más seguros en términos de privacidad,
aun perdiendo en rendimiento.
Clave Foránea (Foreign Key): es un campo en una tabla que hace referencia a la clave primaria de otra tabla,
estableciendo una relación entre ambas. Por ejemplo, en la tabla Order, el campo customer_id puede ser una clave
foránea que referencia la clave primaria id en la tabla Customer, vinculando así cada pedido con el
cliente correspondiente.
Para garantizar la calidad y consistencia de los datos, las bases de datos relacionales implementan restricciones y reglas de integridad:
Integridad de entidad: asegura que cada tabla tenga una clave primaria única, lo que evita duplicados y permite identificar de forma inequívoca cada registro.
Integridad referencial: garantiza que las relaciones entre tablas sean válidas, es decir, que las claves foráneas correspondan a registros existentes en la tabla de referencia. Esta regla evita que existan referencias a registros inexistentes y asegura la coherencia de los datos.
Restricciones de unicidad: estas restricciones aseguran que ciertos campos no tengan valores duplicados, como en el caso de correos electrónicos o números de identificación.
Estos elementos básicos hacen de las bases de datos relacionales una herramienta robusta y versátil para gestionar datos de forma organizada, precisa y consistente. Al comprender estos conceptos fundamentales, los desarrolladores pueden diseñar bases de datos relacionales que respondan eficientemente a los requisitos de sus aplicaciones.
Hemos visto una introducción a las bases de datos, su evolución a lo largo del tiempo y los conceptos clave que sustentan las bases de datos relacionales. En los próximos artículos, profundizaremos en los aspectos más técnicos de las bases de datos relacionales, como el diseño de tablas y las consultas SQL, para que puedas empezar a trabajar con bases de datos en tus propios proyectos. Hasta la próxima y ¡Happy Coding!
Quizá te puedan interesar
Habiendo explorado los fundamentos de Docker y su poder para desplegar aplicaciones encapsuladas, …
leer másEn cualquier sistema operativo, la instalación, actualización y eliminación de software es una tarea …
leer másEn el mundo del desarrollo de aplicaciones móviles garantizar la calidad y la satisfacción del …
leer másDe concepto a realidad