En el artículo anterior construimos un analizador de equipos Pokémon que nos permitió dominar patrones intermedios de n8n: webhooks como puntos de entrada, iteración con Loop Over Items, transformación de datos complejos de APIs y agregación de resultados. Si no lo has leído, te recomiendo hacerlo antes de continuar, aunque este artículo es perfectamente comprensible de forma independiente.
A lo largo de esta serie hemos recorrido un camino bastante completo: empezamos con la configuración inicial de n8n con Docker, después exploramos los tipos de nodos y mejores prácticas, profundizamos en los fundamentos profesionales y por último pusimos en práctica todo eso con un proyecto real. Hoy añadimos una pieza que muchos workflows acaban necesitando tarde o temprano: persistencia de datos.
Hasta ahora todos nuestros workflows eran sin estado (stateless): recibían datos, los procesaban y devolvían un resultado, pero no recordaban nada entre ejecuciones. Eso es suficiente para muchos casos de uso, pero cuando necesitas guardar registros, hacer seguimiento de operaciones anteriores o construir algo parecido a una pequeña base de datos sin depender de servicios externos, las Data Tables de n8n son la herramienta adecuada.
El problema que resuelven
Imagina que quieres construir un sistema de gestión de citas. Cada vez que alguien reserve una cita necesitas guardar esa información en algún sitio para poder consultarla, modificarla o cancelarla más adelante. Las opciones tradicionales serían:
- Usar Google Sheets como base de datos improvisada (funciona, pero tiene límites de velocidad y no es ideal para escrituras frecuentes)
- Integrar Airtable o Notion (añade dependencias externas y posibles costes adicionales)
- Conectar una base de datos real como PostgreSQL o MySQL (requiere infraestructura adicional)
- Usar variables estáticas de n8n (solo sirven para datos de configuración, no para registros dinámicos)
Las Data Tables ofrecen una opción realmente acorde a la casuística: almacenamiento persistente integrado directamente en n8n, sin servicios externos, sin configuración adicional y con un rendimiento más que suficiente para la mayoría de automatizaciones.
¿Qué son las Data Tables en n8n?
Las Data Tables (tablas de datos) son una funcionalidad de n8n que permite almacenar datos estructurados de forma persistente dentro de la propia instancia. Funcionan de forma similar a una tabla de base de datos relacional simplificada: tienen columnas con tipos definidos y filas con registros.
A diferencia de las variables o el almacenamiento de ejecuciones, los datos de una Data Table sobreviven entre ejecuciones y están disponibles para cualquier workflow de tu instancia.
Características principales
- Persistencia real: los datos se mantienen aunque el workflow no esté ejecutándose
- Acceso compartido: cualquier workflow de tu instancia puede leer y escribir en la misma tabla
- Tipos de columna: texto, número, booleano, fecha y JSON
- Operaciones CRUD completas: insertar, consultar, actualizar y eliminar registros
- Filtros y ordenación: puedes consultar registros con condiciones, ordenarlos y paginar resultados
- Sin configuración externa: todo ocurre dentro de n8n, sin necesidad de credenciales adicionales
Las tablas se gestionan desde la pestaña Data Tables de la pantalla de inicio de n8n, junto a Workflows, Credentials, Executions y Variables. Desde ahí puedes crear tablas, definir su esquema y revisar los registros almacenados en cualquier momento. Dentro de los workflows, el acceso Data Tablesse realiza a través del nodo Data Table.
Nota sobre disponibilidad: Las Data Tables están disponibles en n8n Cloud y en instancias self-hosted a partir de la versión 1.113.1. Si tienes una versión anterior, actualiza tu instancia antes de continuar.
Casos de uso principales
Las Data Tables brillan en escenarios donde necesitas estado persistente ligero sin querer añadir dependencias externas:
Registro de eventos y auditoría
Guarda un historial de cada ejecución importante: qué pasó, cuándo, con qué datos y cuál fue el resultado. Útil para auditorías, debugging de producción y reportes periódicos.
{
"timestamp": "2026-04-01T10:30:00Z",
"workflow": "procesamiento-pedidos",
"accion": "pedido_procesado",
"pedido_id": "ORD-2847",
"resultado": "ok",
"duracion_ms": 342
}
Listas de control y deduplicación
Evita procesar el mismo elemento dos veces. Antes de procesar un registro, consulta la tabla para ver si ya fue tratado. Si existe, sáltalo; si no, procésalo y guárdalo.
Un caso típico: un workflow que monitoriza una API y procesa nuevos elementos cada hora necesita recordar qué IDs ya procesó para no duplicar acciones.
Configuración dinámica
Almacena parámetros de configuración que cambian con el tiempo y que deben ser accesibles desde múltiples workflows: umbrales, listas de destinatarios, reglas de negocio, horarios de activación.
A diferencia de las variables estáticas de n8n, aquí puedes actualizar la configuración con un workflow dedicado sin necesidad de editar manualmente los parámetros.
Gestión de colas simples
Implementa una cola de tareas pendientes: un workflow escribe tareas en la tabla con estado pendiente, otro las lee y procesa marcándolas como en_proceso o completada. Simple, efectivo, sin necesidad de Redis o servicios similares.
Gestión básica de entidades
El caso de uso más completo: gestionar registros de una entidad (clientes, productos, reservas, citas) con todas las operaciones CRUD. No sustituye a una base de datos real para proyectos grandes, pero es más que suficiente para automatizaciones de tamaño mediano.
Trabajando con Data Tables: operaciones del nodo
El acceso a las Data Tables desde los workflows se realiza a través del nodo Data Table. Sus operaciones se dividen en dos bloques: acciones sobre filas y acciones sobre la estructura de las tablas.
Acciones sobre filas
Insert row añade un nuevo registro a la tabla. Los valores de cada columna se mapean desde los datos del item en curso mediante expresiones de n8n. El nodo devuelve el registro creado incluyendo el identificador interno que n8n asigna automáticamente a cada fila.
Un detalle importante: n8n no impone restricciones de unicidad. Si necesitas evitar duplicados, la responsabilidad de comprobarlo recae en tu workflow, normalmente mediante una consulta previa.
Get row(s) recupera registros existentes. Admite filtros por valor de columna con condiciones configurables (por ejemplo, Equals), opciones de ordenación, límite de resultados y la posibilidad de devolver todos los registros sin filtro. Cuando el resultado puede estar vacío, activa Always Output Data en el nodo para que el flujo no se detenga por falta de items.
Update row(s) modifica los campos que especifiques dejando el resto intactos. Para actualizar por criterio propio (no por ID interno) el flujo habitual es un Get row(s) previo para localizar la fila, seguido del Update row(s) con el id que devolvió la consulta.
Upsert row(s) combina inserción y actualización en una sola operación: si el registro ya existe lo actualiza; si no existe lo crea. Es la opción más práctica cuando quieres mantener un registro único por algún criterio de negocio sin tener que gestionar manualmente si ya existía o no.
If row exists e If row does not exist son operaciones de validación condicional. Comprueban si existe al menos un registro que cumpla las condiciones indicadas y bifurcan el flujo en consecuencia, sin necesidad de añadir un nodo IF separado. Son especialmente útiles para guardar lógica de negocio del tipo “solo proceder si el usuario ya está registrado” o “solo insertar si este ID no existe todavía”.
Delete row(s) elimina registros de forma permanente según las condiciones que definas. Si necesitas conservar el historial en lugar de borrar, el patrón habitual es actualizar un campo de estado a cancelado o eliminado usando Update row(s), para que el registro permanezca pero quede excluido de las consultas normales.
Acciones sobre tablas
Además de gestionar filas, el nodo Data Table permite administrar la estructura de las propias tablas sin salir de n8n:
- Create a data table: crea una nueva tabla definiendo su nombre y columnas directamente desde el workflow. Útil para onboarding automatizado o para proyectos donde el esquema se genera dinámicamente.
- List data tables: devuelve la lista de tablas disponibles en la instancia. Permite construir workflows que actúen sobre tablas de forma dinámica sin hardcodear sus nombres.
- Update a data table: modifica el nombre o la estructura de una tabla existente.
- Delete a data table: elimina una tabla y todos sus registros de forma permanente.
En la mayoría de los proyectos las tablas se crean y configuran una sola vez desde la interfaz, pero estas operaciones abren la puerta a automatizaciones de gestión más avanzadas, como tablas de staging que se crean, procesan y eliminan de forma programática.
Diseño del esquema
El diseño de las columnas merece pensarse antes de crear la tabla. Una buena práctica es definir solo los campos que realmente necesitarás recuperar, filtrar o comparar; el resto puede consolidarse en un campo JSON genérico. Las columnas que uses en condiciones de búsqueda merecen su tipo correcto desde el principio, porque cambiar el tipo después puede implicar migrar los datos existentes manualmente.
Ejemplo práctico: sistema de reserva de citas
Ahora vamos con el workflow real: un sistema que permite reservar citas con detección automática de conflictos de horario. Un detalle interesante de este ejemplo es que acepta peticiones desde dos fuentes diferentes (un formulario nativo de n8n y un webhook HTTP) y responde de forma apropiada a cada una.
📦 Descargas del ejemplo: Puedes importar el workflow desde appointments.json y la Data Table desde appointments.csv con datos de prueba ya integrados.
Para que el workflow funcione correctamente, la tabla de datos debe existir previamente en tu instancia, ya sea creada a mano o importada desde el CSV anterior. Si al crearla o importarla le asignas un nombre distinto, tendrás que ajustarlo en los nodos del workflow que usan esa Data Table.
Arquitectura del workflow
El workflow tiene dos puntos de entrada que convergen en un único flujo de procesamiento, y tres posibles resultados, cada uno con dos variantes de respuesta según el origen de la petición.
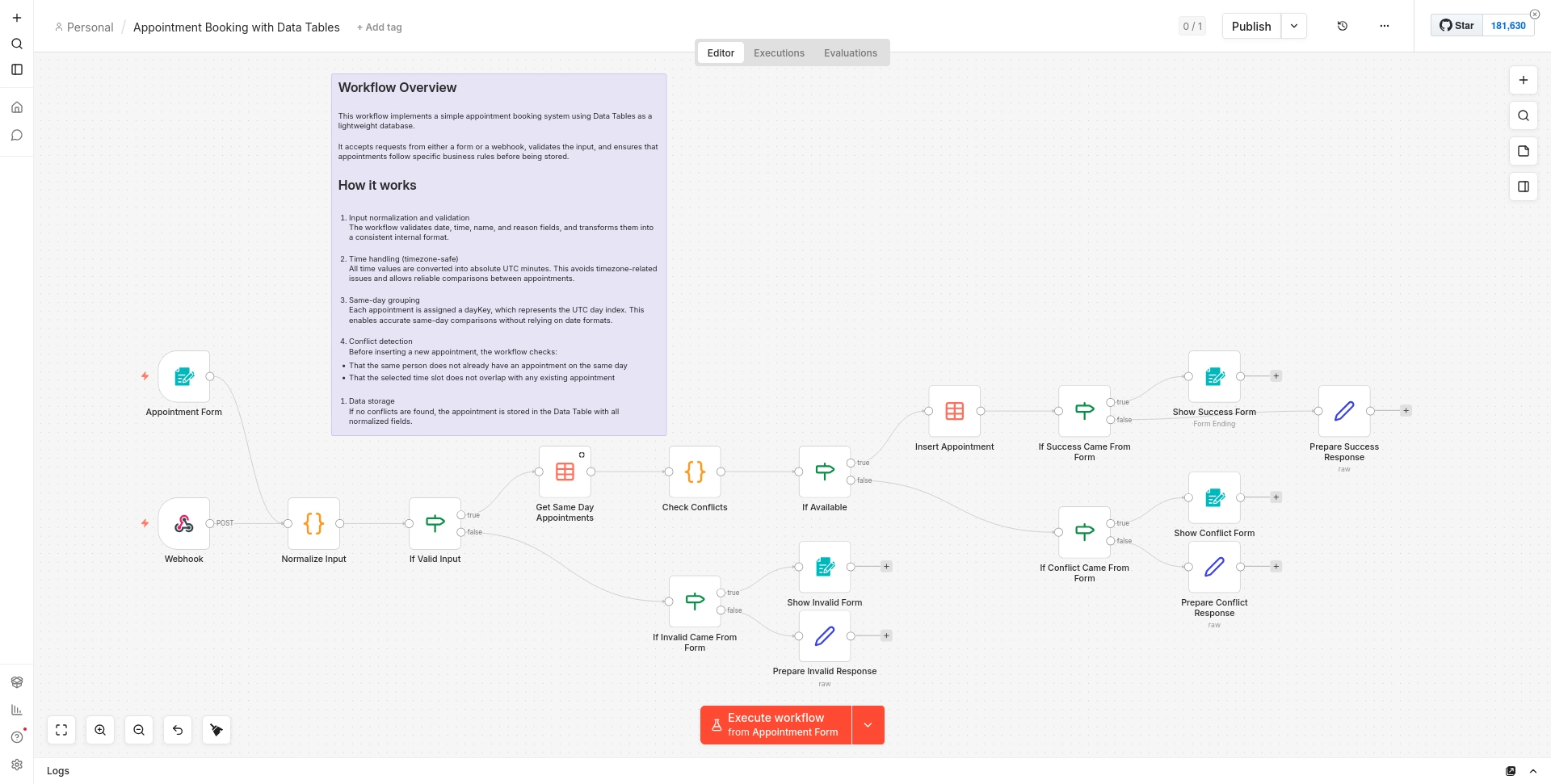
Doble entrada: formulario y webhook
El workflow tiene dos nodos de inicio, lo que lo hace flexible para diferentes casos de uso:
Appointment Form es un formulario nativo de n8n con cuatro campos: fecha (selector de calendario), hora de inicio en formato HH:MM, nombre completo y motivo de la visita. Tiene protección anti-bots activada y usa la zona horaria del workflow. Al completarse, el usuario ve una página de resultado dentro del propio formulario (confirmación, error de validación o conflicto de horario), sin salir de la pantalla.
Webhook POST expone el endpoint /appointments-booking para integraciones externas: aplicaciones web, scripts o cualquier servicio que pueda hacer una petición HTTP. En este caso las respuestas se devuelven como JSON.
Ambos triggers se conectan al mismo nodo. El campo sourceType que genera el nodo siguiente ("form" o "webhook") es el que permite al workflow saber cómo responder al final.
Nodo clave: Normalize Input
Este nodo Code es el corazón del workflow. Hace varias cosas a la vez:
1. Detecta el origen inspeccionando si el cuerpo de la petición viene dentro de un campo body (webhook) o directamente en el raíz (formulario), y registra el resultado en sourceType.
2. Valida los campos de entrada: el formato de fecha debe ser estrictamente YYYY-MM-DD (el nodo rechaza cualquier fecha con componente de hora o zona horaria), la hora debe ser HH:MM, y el nombre y motivo no pueden estar vacíos. Los errores se acumulan en un array errors.
3. Convierte la fecha y hora a minutos UTC absolutos, que es la decisión de diseño más importante de todo el workflow. En lugar de guardar la hora como texto "10:00" o como timestamp con zona horaria, el nodo calcula cuántos minutos han transcurrido desde el epoch UTC (Date.UTC(año, mes, día, hora, minuto) / 60000). Esto produce números como 29.383.200 para el 1 de abril de 2026 a las 10:00 UTC.
¿Por qué? Porque detectar si dos franjas horarias se solapan se reduce entonces a una simple comparación numérica: inicioA < finB && finA > inicioB. Sin zonas horarias, sin parseo de strings, sin ambigüedad.
4. Calcula el dayKey: divide startMinutes entre 1440 (minutos en un día) y toma el entero inferior. Esto produce un número único por día UTC que permite comparar si dos citas son del mismo día sin depender del tipo de columna date en la tabla.
5. Normaliza el nombre: elimina acentos, convierte a minúsculas y descarta cualquier carácter que no sea alfanumérico. "Laura Pérez" y "laura perez" producen el mismo normalizedName, lo que evita duplicados por diferencias de mayúsculas o acentuación.
{
"sourceType": "webhook",
"date": "2026-04-15",
"dayKey": 20558,
"startTime": "10:00",
"endTime": "11:00",
"startMinutes": 29603400,
"endMinutes": 29603460,
"durationMinutes": 60,
"name": "Laura Pérez",
"normalizedName": "lauraperez",
"reason": "Consulta inicial",
"status": "confirmed",
"isValid": true,
"errors": []
}
Get Same Day Appointments
Si la validación pasa, el nodo Data Table recupera todas las filas de la tabla appointments con status = "confirmed". No filtra por fecha en este punto (lo hace el siguiente nodo) porque la columna date es de tipo texto y el filtro de la Data Table no ofrece comparaciones personalizadas. Si esa columna fuese datetime, esta comparación podría hacerse de forma más directa en la propia consulta. El filtrado por día se hace en código, donde se tiene control total.
El nodo tiene activado alwaysOutputData, lo que garantiza que aunque no haya ninguna cita en la tabla el flujo continúa sin errores. Sin esa opción, un resultado vacío detendría la ejecución.
Check Conflicts
Este nodo Code aplica dos reglas de negocio sobre las citas recuperadas:
Regla 1 — una cita por persona por día: compara el normalizedName de la petición entrante con el de cada fila que tenga el mismo dayKey. Si hay coincidencia, el slot está denegado con conflictType: "same_person_same_day".
Regla 2 — no solapamiento de franjas: si la persona no tiene otra cita ese día, comprueba si alguna franja existente se solapa con la solicitada usando la comparación numérica de minutos: reqStart < row._endMinutes && reqEnd > row._startMinutes. Si hay solapamiento con cualquier otra cita (de otra persona), devuelve conflictType: "slot_taken" con el mensaje indicando el horario ocupado.
El nodo también incluye lógica de compatibilidad hacia atrás para leer filas antiguas que pudieran tener los minutos guardados en formato de-minutos-del-día en lugar de minutos absolutos desde epoch, calculando en ese caso el dayKey a partir del campo date.
Insert Appointment
Si no hay conflicto, el nodo Data Table inserta la nueva cita con los diez campos calculados: date, dayKey, startTime, endTime, startMinutes, endMinutes, name, normalizedName, reason y status.
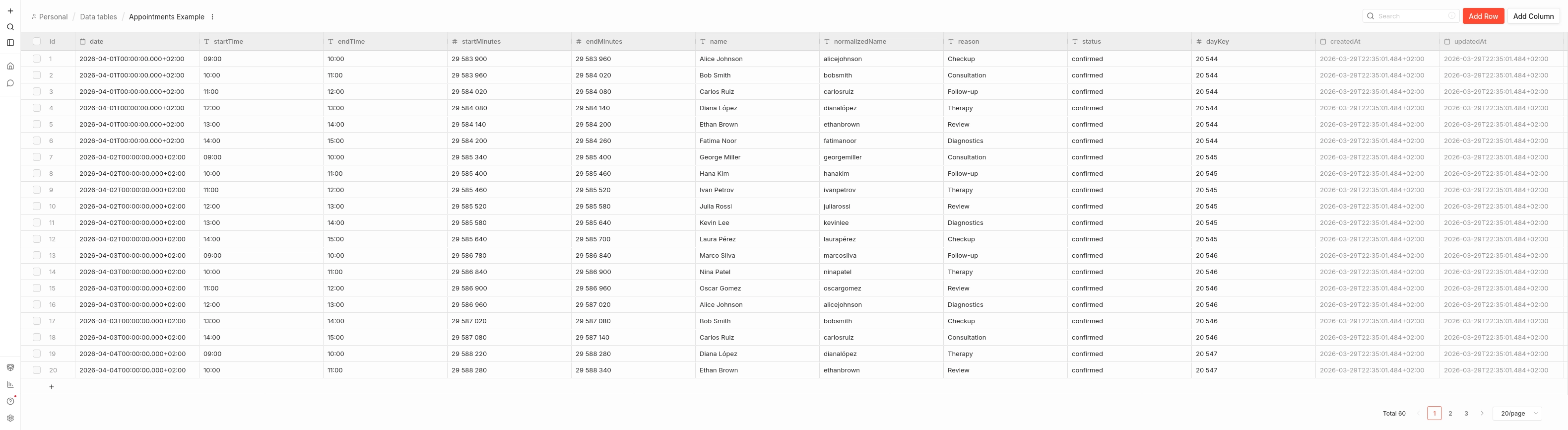
Esquema de la tabla appointments
Si quieres seguir el tutorial con exactamente la misma base de ejemplo, puedes descargar el CSV de appointments, que ya incluye los datos integrados utilizados en este workflow. Si prefieres empezar desde cero, es recomendable definir la columna de fecha (date) como datetime.
| Columna | Tipo | Descripción |
|---|---|---|
date |
text | Fecha en formato YYYY-MM-DD. |
dayKey |
number | Índice de día UTC: floor(startMinutes / 1440) |
startTime |
text | Hora de inicio HH:MM |
endTime |
text | Hora de fin HH:MM |
startMinutes |
number | Minutos UTC absolutos desde epoch (inicio) |
endMinutes |
number | Minutos UTC absolutos desde epoch (fin) |
name |
text | Nombre original del cliente |
normalizedName |
text | Nombre sin acentos ni mayúsculas |
reason |
text | Motivo de la cita |
status |
text | Siempre confirmed en este workflow |
Respuestas según el origen
Cada uno de los tres resultados posibles (cita creada, datos inválidos, conflicto de horario) tiene dos ramas de respuesta, detectadas por un nodo IF que comprueba si sourceType === "form":
| Resultado | Si viene del formulario | Si viene del webhook |
|---|---|---|
| Éxito | Página de confirmación con fecha y hora | { success: true, message: "...", appointment: {...} } |
| Conflicto | Página de error con el horario ocupado | { success: false, conflictType: "slot_taken", message: "..." } |
| Datos inválidos | Página de error con la lista de problemas | { success: false, errors: [...] } |
Los nodos de respuesta de formulario usan la operación completion del nodo Form, que muestra una pantalla de resultado dentro del propio formulario. Los nodos de respuesta JSON usan Set para preparar el objeto y el webhook lo envía como respuesta HTTP.
Probando con curl
Una vez importado el workflow y creada la tabla con el esquema correcto, puedes probarlo directamente:
Reserva válida:
curl -X POST https://tu-n8n.com/webhook/appointments-booking \
-H "Content-Type: application/json" \
-d '{
"date": "2026-04-15",
"time": "10:00",
"name": "Laura Pérez",
"reason": "Consulta inicial"
}'
Respuesta exitosa:
{
"success": true,
"message": "Appointment confirmed for 2026-04-15 from 10:00 to 11:00.",
"appointment": {
"date": "2026-04-15",
"startTime": "10:00",
"endTime": "11:00",
"name": "Laura Pérez",
"reason": "Consulta inicial",
"status": "confirmed"
}
}
Intento de reservar el mismo slot (o solapado):
{
"success": false,
"conflictType": "slot_taken",
"message": "The selected slot is not available. It is already reserved from 10:00 to 11:00."
}
Segunda cita del mismo día para la misma persona:
{
"success": false,
"conflictType": "same_person_same_day",
"message": "Laura Pérez already has an appointment on 2026-04-15 from 10:00 to 11:00."
}
Cuándo usar Data Tables y cuándo no
Las Data Tables son una herramienta poderosa dentro de su ámbito, pero no son la solución correcta para todo.
Úsalas cuando…
- Necesitas persistencia simple dentro de n8n sin dependencias externas
- El volumen de datos es manejable (cientos o pocos miles de registros)
- Los datos son específicos de tus automatizaciones y no necesitan ser accesibles desde otras aplicaciones
- Quieres un prototipo rápido antes de invertir en infraestructura de base de datos real
- Tu caso es temporal o de bajo riesgo y la pérdida de datos no sería crítica
Evítalas cuando…
- Necesitas manejar grandes volúmenes de datos (miles de registros con acceso concurrente frecuente)
- Los datos deben ser accesibles desde otras aplicaciones fuera de n8n
- Necesitas relaciones complejas entre tablas (joins, claves foráneas, integridad referencial)
- Los datos son críticos para el negocio y requieren backups, replicación y garantías de disponibilidad
- Necesitas consultas complejas con agregaciones, agrupaciones o filtros avanzados
Para esos casos, integra una base de datos real. n8n tiene nodos nativos para conectar con PostgreSQL, MySQL, MongoDB, Supabase y muchas otras, con lo que la integración es directa y elegante.
Conclusión
Las Data Tables completan el cuadro de herramientas fundamentales de n8n. Hasta ahora nuestros workflows procesaban datos sin recordar nada; ahora pueden mantener estado, registrar historial y gestionar entidades de forma persistente.
Con esto, la serie de n8n ha cubierto el ciclo completo: instalación, conceptos, buenas prácticas, patrones intermedios y ahora persistencia. Los próximos artículos explorarán integraciones con IA (nodos LLM y AI Agent) y la construcción de automatizaciones más complejas con sub-workflows y módulos reutilizables.
Happy Building!